- 取得連結
- X
- 以電子郵件傳送
- 其他應用程式
ML:基礎技法學習
Package:scikit-learn
課程:機器學習技法
簡介:第六講 Support Vector Regression (SVR)

sklearn.svm.SVR
sklearn.model_selection.learning_curve
Package:scikit-learn
課程:機器學習技法
簡介:第六講 Support Vector Regression (SVR)
Kernel Ridge Regression (KRR)
$$
\begin{align*}
\underset{\boldsymbol\beta}{min}\ \ E_{in}(\boldsymbol\beta) &=\underset{\boldsymbol\beta }{min}\ \ \frac{\lambda}{N}\sum_{n=1}^{N}\sum_{m=1}^{N}\beta _n\beta _mK(\mathbf{x}_n,\mathbf{x}_m)+\frac{1}{N}\sum_{n=1}^{N}\left ( y_n-\sum_{m=1}^{N}\beta_mK(\mathbf{x}_n,\mathbf{x}_m) \right )^2\\
&=\underset{\boldsymbol\beta }{min}\ \ \frac{\lambda}{N}\boldsymbol\beta^T\mathbf{K}\boldsymbol\beta+\frac{1}{N}(\boldsymbol\beta^T \mathbf{K}^T\mathbf{K}\boldsymbol\beta-2\boldsymbol\beta^T \mathbf{K}^T\mathbf{y}+\mathbf{y}^T\mathbf{y})\\
\\
optimal\ \mathbf{w}_*&=\sum_{n=1}^{N}\beta _n\mathbf{z}_n\\
\boldsymbol\beta &= (\lambda\mathbf{I}+\mathbf{K})^{-1}\mathbf{y}
\end{align*}
$$
時間複雜度為 \(O(N^3)\),且 \(\boldsymbol\beta\) 大部分不為 0
L2-regularized linear model
$$ \underset{\mathbf{w}}{min}\ \ \frac{\lambda}{N}\mathbf{w}^T\mathbf{w}+\frac{1}{N}\sum_{n=1}^{N}(y_n-\mathbf{w}^T\mathbf{z}_n)^2 $$ By Representer Theorem optimal \(\mathbf{w}_*=\sum_{n=1}^{N}\beta _n\mathbf{z}_n\)
將 \(\mathbf{w}_*\) 代入
$$ \begin{align*} \underset{\mathbf{w}}{min}\ \ E_{in}(\mathbf{w}) &=\underset{\mathbf{w}}{min}\ \ \frac{\lambda}{N}\mathbf{w}^T\mathbf{w}+E_{in}(\mathbf{w})\\ &=\underset{\mathbf{w}}{min}\ \ \frac{\lambda}{N}\mathbf{w}^T\mathbf{w}+\frac{1}{N}\sum_{n=1}^{N}(y_n-\mathbf{w}^T\mathbf{z}_n)^2\\ (\because \mathbf{w}_*=\sum_{n=1}^{N}\beta _n\mathbf{z}_n=\mathbf{Z}\boldsymbol\beta)\ \underset{\boldsymbol\beta}{min}\ \ E_{in}(\boldsymbol\beta) &= \underset{\boldsymbol\beta}{min}\ \ \frac{\lambda}{N}(\mathbf{Z}\boldsymbol\beta)^T\mathbf{Z}\boldsymbol\beta + \frac{1}{N}\sum_{n=1}^{N} (y_n-(\mathbf{Z}\boldsymbol\beta)^T\mathbf{z}_n)^2\\ &= \underset{\boldsymbol\beta}{min}\ \ \frac{\lambda}{N}\boldsymbol\beta^T\mathbf{Z}^T\mathbf{Z}\boldsymbol\beta + \frac{1}{N}\left \| \mathbf{y}^T-(\mathbf{Z}\boldsymbol\beta)^T\mathbf{Z}\right \|^2\\ &= \underset{\boldsymbol\beta}{min}\ \ \frac{\lambda}{N}\boldsymbol\beta^T\mathbf{Z}^T\mathbf{Z}\boldsymbol\beta + \frac{1}{N}(\mathbf{y}^T-\boldsymbol\beta^T\mathbf{Z}^T\mathbf{Z})(\mathbf{y}^T-\boldsymbol\beta^T\mathbf{Z}^T\mathbf{Z})^T\\ &= \underset{\boldsymbol\beta}{min}\ \ \frac{\lambda}{N}\boldsymbol\beta^T\mathbf{Z}^T\mathbf{Z}\boldsymbol\beta + \frac{1}{N}(\mathbf{y}^T-\boldsymbol\beta^T\mathbf{Z}^T\mathbf{Z})(\mathbf{y}-\mathbf{Z}^T\mathbf{Z}\boldsymbol\beta)\\ &= \underset{\boldsymbol\beta}{min}\ \ \frac{\lambda}{N}\boldsymbol\beta^T\mathbf{Z}^T\mathbf{Z}\boldsymbol\beta + \frac{1}{N}(\mathbf{y}^T\mathbf{y}-\mathbf{y}^T\mathbf{Z}^T\mathbf{Z}\boldsymbol\beta-\boldsymbol\beta^T\mathbf{Z}^T\mathbf{Z}\mathbf{y}+\boldsymbol\beta^T\mathbf{Z}^T\mathbf{Z}\mathbf{Z}^T\mathbf{Z}\boldsymbol\beta)\\ (\because \mathbf{Z}^T\mathbf{Z}=\mathbf{K}) &= \underset{\boldsymbol\beta}{min}\ \ \frac{\lambda}{N}\boldsymbol\beta^T\mathbf{K}\boldsymbol\beta + \frac{1}{N}(\mathbf{y}^T\mathbf{y}-\mathbf{y}^T\mathbf{K}\boldsymbol\beta-\boldsymbol\beta^T\mathbf{K}\mathbf{y}+\boldsymbol\beta^T\mathbf{K}\mathbf{K}\boldsymbol\beta)\\ &= \underset{\boldsymbol\beta}{min}\ \ \frac{\lambda}{N}\boldsymbol\beta^T\mathbf{K}\boldsymbol\beta + \frac{1}{N}(\mathbf{y}^T\mathbf{y}-\mathbf{y}^T\mathbf{K}\boldsymbol\beta-\boldsymbol\beta^T\mathbf{K}\mathbf{y}+\boldsymbol\beta^T\mathbf{K}\mathbf{K}\boldsymbol\beta)\\ &= \underset{\boldsymbol\beta}{min}\ \ \frac{\lambda}{N}\boldsymbol\beta^T\mathbf{K}\boldsymbol\beta + \frac{1}{N}(\mathbf{y}^T\mathbf{y}-2\boldsymbol\beta^T\mathbf{K}\mathbf{y}+\boldsymbol\beta^T\mathbf{K}\mathbf{K}\boldsymbol\beta)\\ (\because \mathbf{K}\ is\ symetric\ \mathbf{K}=\mathbf{K}^T)&= \underset{\boldsymbol\beta}{min}\ \ \frac{\lambda}{N}\boldsymbol\beta^T\mathbf{K}\boldsymbol\beta + \frac{1}{N}(\mathbf{y}^T\mathbf{y}-2\boldsymbol\beta^T\mathbf{K}^T\mathbf{y}+\boldsymbol\beta^T\mathbf{K}^T\mathbf{K}\boldsymbol\beta)\\ &= \underset{\boldsymbol\beta}{min}\ \ \frac{\lambda}{N}\boldsymbol\beta^T\mathbf{K}\boldsymbol\beta + \frac{1}{N}(\boldsymbol\beta^T\mathbf{K}^T\mathbf{K}\boldsymbol\beta-2\boldsymbol\beta^T\mathbf{K}^T\mathbf{y}+\mathbf{y}^T\mathbf{y})\\ \end{align*} $$ 若直接展開如下
$$ \begin{align*} \underset{\mathbf{w}}{min}\ \ E_{in}(\mathbf{w}) &=\underset{\mathbf{w}}{min}\ \ \frac{\lambda}{N}\mathbf{w}^T\mathbf{w}+E_{in}(\mathbf{w})\\ &=\underset{\mathbf{w}}{min}\ \ \frac{\lambda}{N}\mathbf{w}^T\mathbf{w}+\frac{1}{N}\sum_{n=1}^{N}(y_n-\mathbf{w}^T\mathbf{z}_n)^2\\ (\because \mathbf{w}_*=\sum_{n=1}^{N}\beta _n\mathbf{z}_n)\ \underset{\boldsymbol\beta}{min}\ \ E_{in}(\boldsymbol\beta) &=\underset{\mathbf{w}}{min}\ \ \frac{\lambda}{N}\sum_{n=1}^{N}\beta _n\mathbf{z}_n^T\sum_{n=1}^{N}\beta _n\mathbf{z}_n+\frac{1}{N}\sum_{n=1}^{N}(y_n-\sum_{m=1}^{N}\beta _m\mathbf{z}_m^T\mathbf{z}_n)^2\\ &=\underset{\mathbf{w}}{min}\ \ \frac{\lambda}{N}\sum_{n=1}^{N}\sum_{m=1}^{N}\beta _n\beta _m\mathbf{z}_n^T\mathbf{z}_m+\frac{1}{N}\sum_{n=1}^{N}(y_n-\sum_{m=1}^{N}\beta _m\mathbf{z}_m^T\mathbf{z}_n)^2\\ \because (\mathbf{z}_n^T\mathbf{z}_m=\mathbf{K}(\mathbf{x}_n,\mathbf{x}_m))&=\underset{\mathbf{w}}{min}\ \ \frac{\lambda}{N}\sum_{n=1}^{N}\sum_{m=1}^{N}\beta _n\beta _m\mathbf{K}(\mathbf{x}_n,\mathbf{x}_m)+\frac{1}{N}\sum_{n=1}^{N}\left (y_n-\sum_{m=1}^{N}\beta _m\mathbf{K}(\mathbf{x}_m,\mathbf{x}_n)\right )^2\\ \because (\mathbf{K}(\mathbf{x}_m,\mathbf{x}_n)=\mathbf{K}(\mathbf{x}_n,\mathbf{x}_m))&=\underset{\mathbf{w}}{min}\ \ \frac{\lambda}{N}\sum_{n=1}^{N}\sum_{m=1}^{N}\beta _n\beta _m\mathbf{K}(\mathbf{x}_n,\mathbf{x}_m)+\frac{1}{N}\sum_{n=1}^{N}\left (y_n-\sum_{m=1}^{N}\beta _m\mathbf{K}(\mathbf{x}_n,\mathbf{x}_m)\right )^2\\ \end{align*} $$ 借由矩陣微分
$$ \begin{align*} \triangledown E_{in}(\boldsymbol\beta) &= \frac{\partial }{\partial \boldsymbol\beta}\left (\frac{\lambda}{N}\boldsymbol\beta^T\mathbf{K}\boldsymbol\beta + \frac{1}{N}(\boldsymbol\beta^T\mathbf{K}^T\mathbf{K}\boldsymbol\beta-2\boldsymbol\beta^T\mathbf{K}^T\mathbf{y}+\mathbf{y}^T\mathbf{y}) \right )\\ &= \frac{2\lambda}{N}\mathbf{K}\boldsymbol\beta + \frac{1}{N}(2\mathbf{K}^T\mathbf{K}\boldsymbol\beta-2\mathbf{K}^T\mathbf{y})\\ &= \frac{2}{N}(\mathbf{K}\lambda\boldsymbol\beta +\mathbf{K}^T\mathbf{K}\boldsymbol\beta-\mathbf{K}^T\mathbf{y})\\ &= \frac{2}{N}\mathbf{K}^T(\lambda\boldsymbol\beta +\mathbf{K}\boldsymbol\beta-\mathbf{y})\\ &= \frac{2}{N}\mathbf{K}^T((\lambda \mathbf{I} +\mathbf{K})\boldsymbol\beta-\mathbf{y})\\ \end{align*} $$ 區域最佳解,微分等於 0,故
$$ \begin{align*} \triangledown E_{in}(\boldsymbol\beta) &= \frac{2}{N}\mathbf{K}^T((\lambda \mathbf{I} +\mathbf{K})\boldsymbol\beta-\mathbf{y})=0\\ 0&=(\lambda \mathbf{I} +\mathbf{K})\boldsymbol\beta-\mathbf{y}\\ \boldsymbol\beta&=(\lambda \mathbf{I} +\mathbf{K})^{-1}\mathbf{y} \end{align*} $$ 因 \(\lambda >0\) 且 \(\mathbf{K}\) 為半正定,故反矩陣必定存在
時間複雜度為 \(O(N^3)\),且 \(\boldsymbol\beta\) 大部分不為 0
$$ \underset{\mathbf{w}}{min}\ \ \frac{\lambda}{N}\mathbf{w}^T\mathbf{w}+\frac{1}{N}\sum_{n=1}^{N}(y_n-\mathbf{w}^T\mathbf{z}_n)^2 $$ By Representer Theorem optimal \(\mathbf{w}_*=\sum_{n=1}^{N}\beta _n\mathbf{z}_n\)
將 \(\mathbf{w}_*\) 代入
$$ \begin{align*} \underset{\mathbf{w}}{min}\ \ E_{in}(\mathbf{w}) &=\underset{\mathbf{w}}{min}\ \ \frac{\lambda}{N}\mathbf{w}^T\mathbf{w}+E_{in}(\mathbf{w})\\ &=\underset{\mathbf{w}}{min}\ \ \frac{\lambda}{N}\mathbf{w}^T\mathbf{w}+\frac{1}{N}\sum_{n=1}^{N}(y_n-\mathbf{w}^T\mathbf{z}_n)^2\\ (\because \mathbf{w}_*=\sum_{n=1}^{N}\beta _n\mathbf{z}_n=\mathbf{Z}\boldsymbol\beta)\ \underset{\boldsymbol\beta}{min}\ \ E_{in}(\boldsymbol\beta) &= \underset{\boldsymbol\beta}{min}\ \ \frac{\lambda}{N}(\mathbf{Z}\boldsymbol\beta)^T\mathbf{Z}\boldsymbol\beta + \frac{1}{N}\sum_{n=1}^{N} (y_n-(\mathbf{Z}\boldsymbol\beta)^T\mathbf{z}_n)^2\\ &= \underset{\boldsymbol\beta}{min}\ \ \frac{\lambda}{N}\boldsymbol\beta^T\mathbf{Z}^T\mathbf{Z}\boldsymbol\beta + \frac{1}{N}\left \| \mathbf{y}^T-(\mathbf{Z}\boldsymbol\beta)^T\mathbf{Z}\right \|^2\\ &= \underset{\boldsymbol\beta}{min}\ \ \frac{\lambda}{N}\boldsymbol\beta^T\mathbf{Z}^T\mathbf{Z}\boldsymbol\beta + \frac{1}{N}(\mathbf{y}^T-\boldsymbol\beta^T\mathbf{Z}^T\mathbf{Z})(\mathbf{y}^T-\boldsymbol\beta^T\mathbf{Z}^T\mathbf{Z})^T\\ &= \underset{\boldsymbol\beta}{min}\ \ \frac{\lambda}{N}\boldsymbol\beta^T\mathbf{Z}^T\mathbf{Z}\boldsymbol\beta + \frac{1}{N}(\mathbf{y}^T-\boldsymbol\beta^T\mathbf{Z}^T\mathbf{Z})(\mathbf{y}-\mathbf{Z}^T\mathbf{Z}\boldsymbol\beta)\\ &= \underset{\boldsymbol\beta}{min}\ \ \frac{\lambda}{N}\boldsymbol\beta^T\mathbf{Z}^T\mathbf{Z}\boldsymbol\beta + \frac{1}{N}(\mathbf{y}^T\mathbf{y}-\mathbf{y}^T\mathbf{Z}^T\mathbf{Z}\boldsymbol\beta-\boldsymbol\beta^T\mathbf{Z}^T\mathbf{Z}\mathbf{y}+\boldsymbol\beta^T\mathbf{Z}^T\mathbf{Z}\mathbf{Z}^T\mathbf{Z}\boldsymbol\beta)\\ (\because \mathbf{Z}^T\mathbf{Z}=\mathbf{K}) &= \underset{\boldsymbol\beta}{min}\ \ \frac{\lambda}{N}\boldsymbol\beta^T\mathbf{K}\boldsymbol\beta + \frac{1}{N}(\mathbf{y}^T\mathbf{y}-\mathbf{y}^T\mathbf{K}\boldsymbol\beta-\boldsymbol\beta^T\mathbf{K}\mathbf{y}+\boldsymbol\beta^T\mathbf{K}\mathbf{K}\boldsymbol\beta)\\ &= \underset{\boldsymbol\beta}{min}\ \ \frac{\lambda}{N}\boldsymbol\beta^T\mathbf{K}\boldsymbol\beta + \frac{1}{N}(\mathbf{y}^T\mathbf{y}-\mathbf{y}^T\mathbf{K}\boldsymbol\beta-\boldsymbol\beta^T\mathbf{K}\mathbf{y}+\boldsymbol\beta^T\mathbf{K}\mathbf{K}\boldsymbol\beta)\\ &= \underset{\boldsymbol\beta}{min}\ \ \frac{\lambda}{N}\boldsymbol\beta^T\mathbf{K}\boldsymbol\beta + \frac{1}{N}(\mathbf{y}^T\mathbf{y}-2\boldsymbol\beta^T\mathbf{K}\mathbf{y}+\boldsymbol\beta^T\mathbf{K}\mathbf{K}\boldsymbol\beta)\\ (\because \mathbf{K}\ is\ symetric\ \mathbf{K}=\mathbf{K}^T)&= \underset{\boldsymbol\beta}{min}\ \ \frac{\lambda}{N}\boldsymbol\beta^T\mathbf{K}\boldsymbol\beta + \frac{1}{N}(\mathbf{y}^T\mathbf{y}-2\boldsymbol\beta^T\mathbf{K}^T\mathbf{y}+\boldsymbol\beta^T\mathbf{K}^T\mathbf{K}\boldsymbol\beta)\\ &= \underset{\boldsymbol\beta}{min}\ \ \frac{\lambda}{N}\boldsymbol\beta^T\mathbf{K}\boldsymbol\beta + \frac{1}{N}(\boldsymbol\beta^T\mathbf{K}^T\mathbf{K}\boldsymbol\beta-2\boldsymbol\beta^T\mathbf{K}^T\mathbf{y}+\mathbf{y}^T\mathbf{y})\\ \end{align*} $$ 若直接展開如下
$$ \begin{align*} \underset{\mathbf{w}}{min}\ \ E_{in}(\mathbf{w}) &=\underset{\mathbf{w}}{min}\ \ \frac{\lambda}{N}\mathbf{w}^T\mathbf{w}+E_{in}(\mathbf{w})\\ &=\underset{\mathbf{w}}{min}\ \ \frac{\lambda}{N}\mathbf{w}^T\mathbf{w}+\frac{1}{N}\sum_{n=1}^{N}(y_n-\mathbf{w}^T\mathbf{z}_n)^2\\ (\because \mathbf{w}_*=\sum_{n=1}^{N}\beta _n\mathbf{z}_n)\ \underset{\boldsymbol\beta}{min}\ \ E_{in}(\boldsymbol\beta) &=\underset{\mathbf{w}}{min}\ \ \frac{\lambda}{N}\sum_{n=1}^{N}\beta _n\mathbf{z}_n^T\sum_{n=1}^{N}\beta _n\mathbf{z}_n+\frac{1}{N}\sum_{n=1}^{N}(y_n-\sum_{m=1}^{N}\beta _m\mathbf{z}_m^T\mathbf{z}_n)^2\\ &=\underset{\mathbf{w}}{min}\ \ \frac{\lambda}{N}\sum_{n=1}^{N}\sum_{m=1}^{N}\beta _n\beta _m\mathbf{z}_n^T\mathbf{z}_m+\frac{1}{N}\sum_{n=1}^{N}(y_n-\sum_{m=1}^{N}\beta _m\mathbf{z}_m^T\mathbf{z}_n)^2\\ \because (\mathbf{z}_n^T\mathbf{z}_m=\mathbf{K}(\mathbf{x}_n,\mathbf{x}_m))&=\underset{\mathbf{w}}{min}\ \ \frac{\lambda}{N}\sum_{n=1}^{N}\sum_{m=1}^{N}\beta _n\beta _m\mathbf{K}(\mathbf{x}_n,\mathbf{x}_m)+\frac{1}{N}\sum_{n=1}^{N}\left (y_n-\sum_{m=1}^{N}\beta _m\mathbf{K}(\mathbf{x}_m,\mathbf{x}_n)\right )^2\\ \because (\mathbf{K}(\mathbf{x}_m,\mathbf{x}_n)=\mathbf{K}(\mathbf{x}_n,\mathbf{x}_m))&=\underset{\mathbf{w}}{min}\ \ \frac{\lambda}{N}\sum_{n=1}^{N}\sum_{m=1}^{N}\beta _n\beta _m\mathbf{K}(\mathbf{x}_n,\mathbf{x}_m)+\frac{1}{N}\sum_{n=1}^{N}\left (y_n-\sum_{m=1}^{N}\beta _m\mathbf{K}(\mathbf{x}_n,\mathbf{x}_m)\right )^2\\ \end{align*} $$ 借由矩陣微分
$$ \begin{align*} \triangledown E_{in}(\boldsymbol\beta) &= \frac{\partial }{\partial \boldsymbol\beta}\left (\frac{\lambda}{N}\boldsymbol\beta^T\mathbf{K}\boldsymbol\beta + \frac{1}{N}(\boldsymbol\beta^T\mathbf{K}^T\mathbf{K}\boldsymbol\beta-2\boldsymbol\beta^T\mathbf{K}^T\mathbf{y}+\mathbf{y}^T\mathbf{y}) \right )\\ &= \frac{2\lambda}{N}\mathbf{K}\boldsymbol\beta + \frac{1}{N}(2\mathbf{K}^T\mathbf{K}\boldsymbol\beta-2\mathbf{K}^T\mathbf{y})\\ &= \frac{2}{N}(\mathbf{K}\lambda\boldsymbol\beta +\mathbf{K}^T\mathbf{K}\boldsymbol\beta-\mathbf{K}^T\mathbf{y})\\ &= \frac{2}{N}\mathbf{K}^T(\lambda\boldsymbol\beta +\mathbf{K}\boldsymbol\beta-\mathbf{y})\\ &= \frac{2}{N}\mathbf{K}^T((\lambda \mathbf{I} +\mathbf{K})\boldsymbol\beta-\mathbf{y})\\ \end{align*} $$ 區域最佳解,微分等於 0,故
$$ \begin{align*} \triangledown E_{in}(\boldsymbol\beta) &= \frac{2}{N}\mathbf{K}^T((\lambda \mathbf{I} +\mathbf{K})\boldsymbol\beta-\mathbf{y})=0\\ 0&=(\lambda \mathbf{I} +\mathbf{K})\boldsymbol\beta-\mathbf{y}\\ \boldsymbol\beta&=(\lambda \mathbf{I} +\mathbf{K})^{-1}\mathbf{y} \end{align*} $$ 因 \(\lambda >0\) 且 \(\mathbf{K}\) 為半正定,故反矩陣必定存在
時間複雜度為 \(O(N^3)\),且 \(\boldsymbol\beta\) 大部分不為 0
Support Vector Regression (SVR)
Primal
$$ \begin{align*} \underset{\mathbf{b,w,\boldsymbol\xi^\wedge,\boldsymbol\xi^\vee }}{min}\ \ &\frac{1}{2}\mathbf{w}^T\mathbf{w}+C\sum_{n=1}^{N}(\xi_n^\wedge +\xi_n^\vee )\\ s.t.\ \ &-\epsilon -\xi_n^\vee\leq \mathbf{w}^T\mathbf{z}_n+b-y_n\leq \epsilon +\xi_n^\wedge \\ &\xi_n^\vee\geq 0,\ \xi_n^\wedge\geq 0 \end{align*} $$ QP of \(\tilde{d}+1+N\) 個變數,\(2N+2N\) 個條件
Dual
$$ \begin{align*} \underset{\mathbf{\boldsymbol\alpha^\wedge,\boldsymbol\alpha^\vee }}{min}\ \ &\frac{1}{2}\sum_{n=1}^{N}\sum_{m=1}^{N}(\alpha_n^\wedge-\alpha_n^\vee)(\alpha_m^\wedge-\alpha_m^\vee)\mathbf{K}(\mathbf{x}_n,\mathbf{x}_m)+\sum_{n=1}^{N}((\epsilon -y_n)\alpha_n^\wedge+(\epsilon +y_n)\alpha_n^\vee)\\ s.t.\ \ &\sum_{n=1}^{N}(\alpha_n^\wedge-\alpha_n^\vee)=0\\ &0 \le \alpha_n^\wedge \le C,\ 0 \le \alpha_n^\vee \le C,\\ \end{align*} $$ QP of \(2N\) 個變數,\(4N+1\) 個條件
$$ \mathbf{w}=\sum_{n=1}^{N}\underset{\beta_n}{\underbrace{(\alpha_n^\wedge -\alpha_n^\vee)}}\mathbf{z}_n\\ C>\alpha_n^\vee>0\\ b=y_n-\mathbf{w}^T\mathbf{z}_n+\epsilon\\ \\\\ C>\alpha_n^\wedge>0\\ b=y_n-\mathbf{w}^T\mathbf{z}_n-\epsilon\\ $$ 只有在 tube 邊界和以外的才是 SV
$$ \begin{align*} \underset{\mathbf{b,w,\boldsymbol\xi^\wedge,\boldsymbol\xi^\vee }}{min}\ \ &\frac{1}{2}\mathbf{w}^T\mathbf{w}+C\sum_{n=1}^{N}(\xi_n^\wedge +\xi_n^\vee )\\ s.t.\ \ &-\epsilon -\xi_n^\vee\leq \mathbf{w}^T\mathbf{z}_n+b-y_n\leq \epsilon +\xi_n^\wedge \\ &\xi_n^\vee\geq 0,\ \xi_n^\wedge\geq 0 \end{align*} $$ QP of \(\tilde{d}+1+N\) 個變數,\(2N+2N\) 個條件
Dual
$$ \begin{align*} \underset{\mathbf{\boldsymbol\alpha^\wedge,\boldsymbol\alpha^\vee }}{min}\ \ &\frac{1}{2}\sum_{n=1}^{N}\sum_{m=1}^{N}(\alpha_n^\wedge-\alpha_n^\vee)(\alpha_m^\wedge-\alpha_m^\vee)\mathbf{K}(\mathbf{x}_n,\mathbf{x}_m)+\sum_{n=1}^{N}((\epsilon -y_n)\alpha_n^\wedge+(\epsilon +y_n)\alpha_n^\vee)\\ s.t.\ \ &\sum_{n=1}^{N}(\alpha_n^\wedge-\alpha_n^\vee)=0\\ &0 \le \alpha_n^\wedge \le C,\ 0 \le \alpha_n^\vee \le C,\\ \end{align*} $$ QP of \(2N\) 個變數,\(4N+1\) 個條件
$$ \mathbf{w}=\sum_{n=1}^{N}\underset{\beta_n}{\underbrace{(\alpha_n^\wedge -\alpha_n^\vee)}}\mathbf{z}_n\\ C>\alpha_n^\vee>0\\ b=y_n-\mathbf{w}^T\mathbf{z}_n+\epsilon\\ \\\\ C>\alpha_n^\wedge>0\\ b=y_n-\mathbf{w}^T\mathbf{z}_n-\epsilon\\ $$ 只有在 tube 邊界和以外的才是 SV
希望 \(\beta\) 的特性與 \(\alpha\) 一樣,大部分皆是 0
首先重新定義 err 從 square regression 改為 tube regression
 也就是當錯誤在水管範圍內,則視為沒有錯誤,也就是 \(|s-y| \le \epsilon\) 時,err=0
也就是當錯誤在水管範圍內,則視為沒有錯誤,也就是 \(|s-y| \le \epsilon\) 時,err=0
若超過時,則扣掉水管範圍部分,也就是 \(|s-y| > \epsilon\) 時,err=\(|s-y|-\epsilon\)
可得 \(err(y,s)=max(0,|s-y|-\epsilon)\)
如圖,可看到 err 在兩者接近 s 時,大約相同,遠離時 tube 成長幅度比較沒那麼劇烈

 於是得到 L2-Regularized Tube Regression
於是得到 L2-Regularized Tube Regression
$$ \underset{\mathbf{w}}{min}\ \ \frac{\lambda}{N}\mathbf{w}^T\mathbf{w}+\frac{1}{N}\sum_{n=1}^{N}max(0,|\mathbf{w}^T\mathbf{z}_n-y_n|-\epsilon ) $$ 為了更接近標準的 SVM 定義,重新調整參數
$$ \begin{align*} &\underset{\mathbf{w}}{min}\ \ \frac{\lambda}{N}\mathbf{w}^T\mathbf{w}+\frac{1}{N}\sum_{n=1}^{N}max(0,|\mathbf{w}^T\mathbf{z}_n-y_n|-\epsilon ) \\ \Rightarrow\ \ &\underset{\mathbf{w}}{min}\ \ \frac{\lambda}{2N}\mathbf{w}^T\mathbf{w}+\frac{1}{2N}\sum_{n=1}^{N}max(0,|\mathbf{w}^T\mathbf{z}_n-y_n|-\epsilon ) \\ \because \lambda >0\Rightarrow\ \ &\underset{\mathbf{w}}{min}\ \ \frac{1}{2N}\mathbf{w}^T\mathbf{w}+\frac{1}{2N\lambda}\sum_{n=1}^{N}max(0,|\mathbf{w}^T\mathbf{z}_n-y_n|-\epsilon ) \\ \because N >0\Rightarrow\ \ &\underset{\mathbf{w}}{min}\ \ \frac{1}{2}\mathbf{w}^T\mathbf{w}+\frac{1}{2\lambda}\sum_{n=1}^{N}max(0,|\mathbf{w}^T\mathbf{z}_n-y_n|-\epsilon ) \\ \Rightarrow\ \ &\underset{\mathbf{w}}{min}\ \ \frac{1}{2}\mathbf{w}^T\mathbf{w}+C\sum_{n=1}^{N}max(0,|\mathbf{w}^T\mathbf{z}_n-y_n|-\epsilon ) \\ \Rightarrow\ \ &\underset{b,\mathbf{w}}{min}\ \ \frac{1}{2}\mathbf{w}^T\mathbf{w}+C\sum_{n=1}^{N}max(0,|\mathbf{w}^T\mathbf{z}_n+b-y_n|-\epsilon ) \\ \end{align*} $$ 最後加上 \(b\) 的原因,是為了更加符合標準的定義,且因為加上 \(b\) 但又對其最小化,不影響原先結果
用 \(\xi_n\) 表達錯誤,重新定義方程式,當 \(|\mathbf{w}^T\mathbf{z}_n+b-y_n|\le\epsilon\) 時,\(\xi_n=0\),不然就 \(\xi_n>0\)
$$ \begin{align*} &\underset{b,\mathbf{w}}{min}\ \ \frac{1}{2}\mathbf{w}^T\mathbf{w}+C\sum_{n=1}^{N}max(0,|\mathbf{w}^T\mathbf{z}_n+b-y_n|-\epsilon ) \\ \Rightarrow\ \ &\underset{b,\mathbf{w},\boldsymbol\xi}{min}\ \ \frac{1}{2}\mathbf{w}^T\mathbf{w}+C\sum_{n=1}^{N}\xi_n\\ &s.t.\ \ |\mathbf{w}^T\mathbf{z}_n+b-y_n|\le\epsilon+\xi_n\\ &\ \ \ \ \ \ \xi_n \ge 0\\ \end{align*} $$ 絕對值仍存在,還不是線性方程式,故再將之展開,並將 \(\xi_n\) 定義上下限
且將 \(|\mathbf{w}^T\mathbf{z}_n+b-y_n|\) 反向,符合常用定義
$$ \begin{align*} &\underset{b,\mathbf{w},\boldsymbol\xi}{min}\ \ \frac{1}{2}\mathbf{w}^T\mathbf{w}+C\sum_{n=1}^{N}\xi_n\\ &s.t.\ \ |\mathbf{w}^T\mathbf{z}_n+b-y_n|\le\epsilon+\xi_n\\ &\ \ \ \ \ \ \ \ \ \ \xi_n \ge 0\\ \Rightarrow\ \ &\underset{b,\mathbf{w},\boldsymbol\xi^\vee,\boldsymbol\xi^\wedge}{min}\ \ \frac{1}{2}\mathbf{w}^T\mathbf{w}+C\sum_{n=1}^{N}(\xi_n^\vee +\xi_n^\wedge) \\ &s.t.\ \ \ \ \ \ -\epsilon-\xi_n^\vee\le y_n-\mathbf{w}^T\mathbf{z}_n-b\le\epsilon+\xi_n^\wedge\\ &\ \ \ \ \ \ \ \ \ \ \ \ \ \ \xi_n^\vee \ge 0,\ \xi_n^\wedge \ge 0 \end{align*} $$ 故可得 primal,QP of \(\tilde{d}+1+N\) 個變數,\(2N+2N\) 個條件
但這還不是想要的,dual 又該如何得到呢?
利用 Lagrange multipliers,隱藏限制條件,此處將 \(\lambda _n\) 用 \(\alpha _n^\wedge\) & \(\alpha _n^\vee\) & \(\beta_n^\wedge\) & \(\beta_n^\vee\) 取代
$$ L(b,\mathbf{w},\boldsymbol\xi^\vee ,\boldsymbol\xi^\wedge,\boldsymbol\alpha^\vee,\boldsymbol\alpha^\wedge,\boldsymbol\beta^\vee,\boldsymbol\beta^\wedge)=\frac{1}{2}\mathbf{w}^T\mathbf{w}+C\cdot \sum_{n=1}^{N}(\xi _n^\vee +\xi _n^\wedge )+\sum_{n=1}^{N}\alpha _n^\vee (-y_n+\mathbf{w}^T\mathbf{z}_n+b-\epsilon-\xi_n^\vee)+\sum_{n=1}^{N}\alpha _n^\wedge (y_n-\mathbf{w}^T\mathbf{z}_n-b-\epsilon-\xi_n^\wedge)+\sum_{n=1}^{N}\beta_n^\wedge\cdot (-\xi_n^\wedge)+\sum_{n=1}^{N}\beta_n^\vee\cdot (-\xi_n^\vee) $$ 當 \(\underset{all\ \alpha_n^\vee \geq 0,\alpha_n^\wedge \ge 0,\beta_n^\vee \geq 0,\beta_n^\wedge\ge 0}{max}\ L(b,\mathbf{w},\boldsymbol\xi^\vee ,\boldsymbol\xi^\wedge,\boldsymbol\alpha^\vee,\boldsymbol\alpha^\wedge,\boldsymbol\beta^\vee,\boldsymbol\beta^\wedge)\) 會發現
$$ SVM\equiv \underset{b,\mathbf{w},\boldsymbol\xi^\vee ,\boldsymbol\xi^\wedge}{min}\left (\underset{all\ \alpha_n^\vee \geq 0,\alpha_n^\wedge \ge 0,\beta_n^\vee \geq 0,\beta_n^\wedge\ge 0}{max}\ L(b,\mathbf{w},\boldsymbol\xi^\vee ,\boldsymbol\xi^\wedge,\boldsymbol\alpha^\vee,\boldsymbol\alpha^\wedge,\boldsymbol\beta^\vee,\boldsymbol\beta^\wedge) \right )=\underset{b,\mathbf{w},\boldsymbol\xi^\vee ,\boldsymbol\xi^\wedge}{min}\left (\infty\ if\ violate;\frac{1}{2}\mathbf{w}^T\mathbf{w}\ if\ feasible \right ) $$
此時 \((b,\mathbf{w},\boldsymbol\xi^\vee ,\boldsymbol\xi^\wedge)\) 仍在式子最外面,如何把它跟裡面的 \(\alpha _n^\wedge,\alpha _n^\vee,\beta _n^\wedge,\beta _n^\vee \) 交換呢?
這樣才能初步得到 4N 個變數的式子
任取一個 \(\boldsymbol{\alpha}'^\vee,\boldsymbol{\alpha}'^\wedge,\boldsymbol{\beta}'^\vee,\boldsymbol{\beta}'^\wedge\) with \({\alpha}'^\vee_n \ge 0,{\alpha}'^\wedge_n \ge 0,{\beta}'^\vee_n \ge 0,{\beta}'^\wedge_n \ge 0\)
因取 max 一定比任意還大,可得下式
\(\underset{b,\mathbf{w},\boldsymbol\xi^\vee ,\boldsymbol\xi^\wedge}{min}\left (\underset{all\ \alpha_n^\vee \geq 0,\alpha_n^\wedge \ge 0,\beta_n^\vee \geq 0,\beta_n^\wedge\ge 0}{max}\ L(b,\mathbf{w},\boldsymbol\xi^\vee ,\boldsymbol\xi^\wedge,\boldsymbol\alpha^\vee,\boldsymbol\alpha^\wedge,\boldsymbol\beta^\vee,\boldsymbol\beta^\wedge) \right ) \geq \underset{b,\mathbf{w},\boldsymbol\xi^\vee ,\boldsymbol\xi^\wedge}{min}\ L(b,\mathbf{w},\boldsymbol\xi^\vee ,\boldsymbol\xi^\wedge,\boldsymbol{\alpha}'^\vee,\boldsymbol{\alpha}'^\wedge,\boldsymbol{\beta}'^\vee,\boldsymbol{\beta}'^\wedge)\)
那如果對 \(\boldsymbol{\alpha}'^\vee \ge 0,\boldsymbol{\alpha}'^\wedge \ge 0,\boldsymbol{\beta}'^\vee \ge 0,\boldsymbol{\beta}'^\wedge \ge 0\) 取 max,也不影響此等式,如下
\(\underset{b,\mathbf{w},\boldsymbol\xi^\vee ,\boldsymbol\xi^\wedge}{min}\left (\underset{all\ \alpha_n^\vee \geq 0,\alpha_n^\wedge \ge 0,\beta_n^\vee \geq 0,\beta_n^\wedge\ge 0}{max}\ L(b,\mathbf{w},\boldsymbol\xi^\vee ,\boldsymbol\xi^\wedge,\boldsymbol\alpha^\vee,\boldsymbol\alpha^\wedge,\boldsymbol\beta^\vee,\boldsymbol\beta^\wedge) \right ) \geq \underset{Lagrange\ dual\ problem}{\underbrace{\underset{all\ \boldsymbol{\alpha}'^\vee \ge 0,\boldsymbol{\alpha}'^\wedge \ge 0,\boldsymbol{\beta}'^\vee \ge 0,\boldsymbol{\beta}'^\wedge \ge 0}{max}\left (\underset{b,\mathbf{w},\boldsymbol\xi^\vee ,\boldsymbol\xi^\wedge}{min}\ L(b,\mathbf{w},\boldsymbol\xi^\vee ,\boldsymbol\xi^\wedge,\boldsymbol{\alpha}'^\vee,\boldsymbol{\alpha}'^\wedge,\boldsymbol{\beta}'^\vee,\boldsymbol{\beta}'^\wedge) \right )\overset{\boldsymbol{\alpha}'^\vee=\boldsymbol\alpha^\vee,\boldsymbol{\alpha}'^\wedge=\boldsymbol\alpha^\wedge,\boldsymbol{\beta}'^\vee=\boldsymbol\beta^\vee,\boldsymbol{\beta}'^\wedge=\boldsymbol\beta^\wedge}{\rightarrow} \underset{all\ \alpha_n^\vee \geq 0,\alpha_n^\wedge \ge 0,\beta_n^\vee \geq 0,\beta_n^\wedge\ge 0}{max}\left (\underset{b,\mathbf{w},\boldsymbol\xi^\vee ,\boldsymbol\xi^\wedge}{min}\ L(b,\mathbf{w},\boldsymbol\xi^\vee ,\boldsymbol\xi^\wedge,\boldsymbol\alpha^\vee,\boldsymbol\alpha^\wedge,\boldsymbol\beta^\vee,\boldsymbol\beta^\wedge) \right )}}\)
比較直覺的想法,就像是「從最大的一群中取最小」一定 \(\ge\) 「從最小的一群中取最大」
$$ \underset{original(primal))\ SVM}{\underbrace{\underset{b,\mathbf{w},\boldsymbol\xi^\vee ,\boldsymbol\xi^\wedge}{min}\left (\underset{all\ \alpha_n^\vee \geq 0,\alpha_n^\wedge \ge 0,\beta_n^\vee \geq 0,\beta_n^\wedge\ge 0}{max}\ L(b,\mathbf{w},\boldsymbol\xi^\vee ,\boldsymbol\xi^\wedge,\boldsymbol\alpha^\vee,\boldsymbol\alpha^\wedge,\boldsymbol\beta^\vee,\boldsymbol\beta^\wedge) \right )}} \geq \underset{Lagrange\ dual}{\underbrace{ \underset{all\ \alpha_n^\vee \geq 0,\alpha_n^\wedge \ge 0,\beta_n^\vee \geq 0,\beta_n^\wedge\ge 0}{max}\left (\underset{b,\mathbf{w},\boldsymbol\xi^\vee ,\boldsymbol\xi^\wedge}{min}\ L(b,\mathbf{w},\boldsymbol\xi^\vee ,\boldsymbol\xi^\wedge,\boldsymbol\alpha^\vee,\boldsymbol\alpha^\wedge,\boldsymbol\beta^\vee,\boldsymbol\beta^\wedge) \right )}} $$ 目前的關係稱作 \(\ge\) weak duality
但這還不夠,最好是 \(=\) strong duality,才能初步得到 4N 個變數的式子
幸運的是,在 QP 中,只要滿足以下條件,便是 strong duality
$$ \underset{all\ \alpha_n^\vee \geq 0,\alpha_n^\wedge \ge 0,\beta_n^\vee \geq 0,\beta_n^\wedge\ge 0}{max}\left (\underset{b,\mathbf{w},\boldsymbol\xi^\vee ,\boldsymbol\xi^\wedge}{min}\ \underset{L(b,\mathbf{w},\boldsymbol\xi^\vee ,\boldsymbol\xi^\wedge,\boldsymbol\alpha^\vee,\boldsymbol\alpha^\wedge,\boldsymbol\beta^\vee,\boldsymbol\beta^\wedge)}{\underbrace{\frac{1}{2}\mathbf{w}^T\mathbf{w}+C\cdot \sum_{n=1}^{N}(\xi _n^\vee +\xi _n^\wedge )+\sum_{n=1}^{N}\alpha _n^\vee (-y_n+\mathbf{w}^T\mathbf{z}_n+b-\epsilon-\xi_n^\vee)+\sum_{n=1}^{N}\alpha _n^\wedge (y_n-\mathbf{w}^T\mathbf{z}_n-b-\epsilon-\xi_n^\wedge)+\sum_{n=1}^{N}\beta_n^\wedge\cdot (-\xi_n^\wedge)+\sum_{n=1}^{N}\beta_n^\vee\cdot (-\xi_n^\vee)}}\right ) $$
但如何把內部的 \((b,\mathbf{w},\boldsymbol\xi^\vee ,\boldsymbol\xi^\wedge)\) 拿掉呢?
內部的問題,當最佳化時,必定符合
$$ \begin{align*} \frac{\partial L(b,\mathbf{w},\boldsymbol\xi^\vee ,\boldsymbol\xi^\wedge,\boldsymbol\alpha^\vee,\boldsymbol\alpha^\wedge,\boldsymbol\beta^\vee,\boldsymbol\beta^\wedge)}{\partial b}&=0=\sum_{n=1}^{N}(\alpha_n^\vee-\alpha_n^\wedge) \Rightarrow \sum_{n=1}^{N}(\alpha_n^\wedge-\alpha_n^\vee)=0\\ \frac{\partial L(b,\mathbf{w},\boldsymbol\xi^\vee ,\boldsymbol\xi^\wedge,\boldsymbol\alpha^\vee,\boldsymbol\alpha^\wedge,\boldsymbol\beta^\vee,\boldsymbol\beta^\wedge)}{\partial \mathbf{w}}&=\mathbf{0}=\mathbf{w}+\sum_{n=1}^{N}\alpha _n^\vee\mathbf{z}_n-\sum_{n=1}^{N}\alpha _n^\wedge\mathbf{z}_n \Rightarrow \mathbf{w}=\sum_{n=1}^{N}\underset{\beta_n}{\underbrace{(\alpha _n^\wedge-\alpha _n^\vee)}}\mathbf{z}_n\\ \frac{\partial L(b,\mathbf{w},\boldsymbol\xi^\vee ,\boldsymbol\xi^\wedge,\boldsymbol\alpha^\vee,\boldsymbol\alpha^\wedge,\boldsymbol\beta^\vee,\boldsymbol\beta^\wedge)}{\partial \xi^\vee}&=0=C-\alpha _n^\vee-\beta _n^\vee \Rightarrow \beta_n^\vee=C-\alpha_n^\vee\\ \frac{\partial L(b,\mathbf{w},\boldsymbol\xi^\vee ,\boldsymbol\xi^\wedge,\boldsymbol\alpha^\vee,\boldsymbol\alpha^\wedge,\boldsymbol\beta^\vee,\boldsymbol\beta^\wedge)}{\partial \xi^\wedge}&=0=C-\alpha _n^\wedge-\beta _n^\wedge \Rightarrow \beta_n^\wedge=C-\alpha_n^\wedge\\ \end{align*} $$ 從以上的這些條件,可得
$$ \begin{align*} dual&=\underset{all\ \alpha_n^\vee \geq 0,\alpha_n^\wedge \ge 0,\beta_n^\vee \geq 0,\beta_n^\wedge\ge 0}{max}\left (\underset{b,\mathbf{w},\boldsymbol\xi^\vee ,\boldsymbol\xi^\wedge}{min}\ \frac{1}{2}\mathbf{w}^T\mathbf{w}+C\cdot \sum_{n=1}^{N}(\xi _n^\vee +\xi _n^\wedge )+\sum_{n=1}^{N}\alpha _n^\vee (-y_n+\mathbf{w}^T\mathbf{z}_n+b-\epsilon-\xi_n^\vee)+\sum_{n=1}^{N}\alpha _n^\wedge (y_n-\mathbf{w}^T\mathbf{z}_n-b-\epsilon-\xi_n^\wedge)+\sum_{n=1}^{N}\beta_n^\wedge\cdot (-\xi_n^\wedge)+\sum_{n=1}^{N}\beta_n^\vee\cdot (-\xi_n^\vee)\right ) \\ &=\underset{all\ \alpha_n^\vee \geq 0,\alpha_n^\wedge \ge 0,\beta_n^\vee \geq 0,\beta_n^\wedge\ge 0}{max}\left (\underset{b,\mathbf{w},\boldsymbol\xi^\vee ,\boldsymbol\xi^\wedge}{min}\ \frac{1}{2}\mathbf{w}^T\mathbf{w}+C\cdot \sum_{n=1}^{N}(\xi _n^\vee +\xi _n^\wedge)+\sum_{n=1}^{N}(\alpha _n^\vee\cdot - \xi_n^\vee+\alpha _n^\wedge\cdot - \xi_n^\wedge) +\sum_{n=1}^{N}\alpha _n^\vee (-y_n+\mathbf{w}^T\mathbf{z}_n+b-\epsilon)+\sum_{n=1}^{N}\alpha _n^\wedge (y_n-\mathbf{w}^T\mathbf{z}_n-b-\epsilon)+\sum_{n=1}^{N}\beta_n^\wedge\cdot (-\xi_n^\wedge)+\sum_{n=1}^{N}\beta_n^\vee\cdot (-\xi_n^\vee)\right )\\ &=\underset{all\ \alpha_n^\vee \geq 0,\alpha_n^\wedge \ge 0,\beta_n^\vee =C-\alpha_n^\vee,\beta_n^\wedge=C-\alpha_n^\wedge}{max}\left (\underset{b,\mathbf{w},\boldsymbol\xi^\vee ,\boldsymbol\xi^\wedge}{min}\ \frac{1}{2}\mathbf{w}^T\mathbf{w}+\sum_{n=1}^{N}((C-\alpha _n^\vee-\beta_n^\vee)\xi _n^\vee +(C-\alpha _n^\wedge-\beta_n^\wedge)\xi _n^\wedge)+\sum_{n=1}^{N}\alpha _n^\vee (-y_n+\mathbf{w}^T\mathbf{z}_n+b-\epsilon)+\sum_{n=1}^{N}\alpha _n^\wedge (y_n-\mathbf{w}^T\mathbf{z}_n-b-\epsilon)\right )\\ [\because 0=C-\alpha _n^\wedge-\beta _n^\wedge,0=C-\alpha _n^\vee-\beta _n^\vee]&=\underset{all\ \alpha_n^\vee \geq 0,\alpha_n^\wedge \ge 0,\beta_n^\vee \geq 0,\beta_n^\wedge\ge 0}{max}\left (\underset{b,\mathbf{w},\boldsymbol\xi^\vee ,\boldsymbol\xi^\wedge}{min}\ \frac{1}{2}\mathbf{w}^T\mathbf{w}+\sum_{n=1}^{N}\alpha _n^\vee (-y_n+\mathbf{w}^T\mathbf{z}_n+b-\epsilon)+\sum_{n=1}^{N}\alpha _n^\wedge (y_n-\mathbf{w}^T\mathbf{z}_n-b-\epsilon)\right )\\ [\because \beta _n^\wedge \ge 0\Rightarrow \alpha_n^\wedge \le C,\beta _n^\vee \ge 0\Rightarrow \alpha_n^\vee \le C]&=\underset{all\ C \ge\alpha_n^\vee \geq 0,C \ge\alpha_n^\wedge \ge 0,\beta_n^\vee =C-\alpha_n^\vee,\beta_n^\wedge=C-\alpha_n^\wedge}{max}\left (\underset{b,\mathbf{w},\boldsymbol\xi^\vee ,\boldsymbol\xi^\wedge}{min}\ \frac{1}{2}\mathbf{w}^T\mathbf{w}+\sum_{n=1}^{N}\alpha _n^\vee (-y_n+\mathbf{w}^T\mathbf{z}_n+b-\epsilon)+\sum_{n=1}^{N}\alpha _n^\wedge (y_n-\mathbf{w}^T\mathbf{z}_n-b-\epsilon)\right )\\ &=\underset{all\ C \ge\alpha_n^\vee \geq 0,C \ge\alpha_n^\wedge \ge 0,\beta_n^\vee =C-\alpha_n^\vee,\beta_n^\wedge=C-\alpha_n^\wedge}{max}\left (\underset{b,\mathbf{w},\boldsymbol\xi^\vee ,\boldsymbol\xi^\wedge}{min}\ \frac{1}{2}\mathbf{w}^T\mathbf{w}+\sum_{n=1}^{N}(\alpha _n^\wedge -\alpha _n^\vee) (-b)+\sum_{n=1}^{N}\alpha _n^\vee (-y_n+\mathbf{w}^T\mathbf{z}_n-\epsilon)+\sum_{n=1}^{N}\alpha _n^\wedge (y_n-\mathbf{w}^T\mathbf{z}_n-\epsilon)\right )\\ [\because \sum_{n=1}^{N}(\alpha _n^\wedge -\alpha _n^\vee)=0] &= \underset{all\ C \ge\alpha_n^\vee \geq 0,C \ge\alpha_n^\wedge \ge 0,\beta_n^\vee =C-\alpha_n^\vee,\beta_n^\wedge=C-\alpha_n^\wedge,\sum_{n=1}^{N}(\alpha _n^\wedge -\alpha _n^\vee)=0}{max}\left (\underset{b,\mathbf{w},\boldsymbol\xi^\vee ,\boldsymbol\xi^\wedge}{min}\ \frac{1}{2}\mathbf{w}^T\mathbf{w}+\sum_{n=1}^{N}\alpha _n^\vee (-y_n+\mathbf{w}^T\mathbf{z}_n-\epsilon)+\sum_{n=1}^{N}\alpha _n^\wedge (y_n-\mathbf{w}^T\mathbf{z}_n-\epsilon)\right )\\ &= \underset{all\ C \ge\alpha_n^\vee \geq 0,C \ge\alpha_n^\wedge \ge 0,\beta_n^\vee =C-\alpha_n^\vee,\beta_n^\wedge=C-\alpha_n^\wedge,\sum_{n=1}^{N}(\alpha _n^\wedge -\alpha _n^\vee)=0}{max}\left (\underset{b,\mathbf{w},\boldsymbol\xi^\vee ,\boldsymbol\xi^\wedge}{min}\ \frac{1}{2}\mathbf{w}^T\mathbf{w}+\sum_{n=1}^{N}(\alpha _n^\wedge-\alpha _n^\vee)(-\mathbf{w}^T\mathbf{z}_n)+\sum_{n=1}^{N}\alpha _n^\vee (-y_n-\epsilon)+\sum_{n=1}^{N}\alpha _n^\wedge (y_n-\epsilon)\right )\\ &= \underset{all\ C \ge\alpha_n^\vee \geq 0,C \ge\alpha_n^\wedge \ge 0,\beta_n^\vee =C-\alpha_n^\vee,\beta_n^\wedge=C-\alpha_n^\wedge,\sum_{n=1}^{N}(\alpha _n^\wedge -\alpha _n^\vee)=0}{max}\left (\underset{b,\mathbf{w},\boldsymbol\xi^\vee ,\boldsymbol\xi^\wedge}{min}\ \frac{1}{2}\mathbf{w}^T\mathbf{w}+\sum_{n=1}^{N}-\mathbf{w}^T(\alpha _n^\wedge-\alpha _n^\vee)\mathbf{z}_n+\sum_{n=1}^{N}\alpha _n^\vee (-y_n-\epsilon)+\sum_{n=1}^{N}\alpha _n^\wedge (y_n-\epsilon)\right )\\ \end{align*} $$ $$ \begin{align*} [\because \mathbf{w}=\sum_{n=1}^{N}(\alpha _n^\wedge-\alpha _n^\vee)\mathbf{z}_n] &= \underset{all\ C \ge\alpha_n^\vee \geq 0,C \ge\alpha_n^\wedge \ge 0,\beta_n^\vee =C-\alpha_n^\vee,\beta_n^\wedge=C-\alpha_n^\wedge,\sum_{n=1}^{N}(\alpha _n^\wedge -\alpha _n^\vee)=0,\mathbf{w}=\sum_{n=1}^{N}(\alpha _n^\wedge-\alpha _n^\vee)\mathbf{z}_n}{max}\left (\underset{b,\mathbf{w},\boldsymbol\xi^\vee ,\boldsymbol\xi^\wedge}{min}\ \frac{1}{2}\mathbf{w}^T\mathbf{w}-\mathbf{w}^T\mathbf{w}+\sum_{n=1}^{N}\alpha _n^\vee (-y_n-\epsilon)+\sum_{n=1}^{N}\alpha _n^\wedge (y_n-\epsilon)\right )\\ &= \underset{all\ C \ge\alpha_n^\vee \geq 0,C \ge\alpha_n^\wedge \ge 0,\beta_n^\vee =C-\alpha_n^\vee,\beta_n^\wedge=C-\alpha_n^\wedge,\sum_{n=1}^{N}(\alpha _n^\wedge -\alpha _n^\vee)=0,\mathbf{w}=\sum_{n=1}^{N}(\alpha _n^\wedge-\alpha _n^\vee)\mathbf{z}_n}{max}\left (\underset{b,\mathbf{w},\boldsymbol\xi^\vee ,\boldsymbol\xi^\wedge}{min}\ -\frac{1}{2}\mathbf{w}^T\mathbf{w}+\sum_{n=1}^{N}\alpha _n^\vee (-y_n-\epsilon)+\alpha _n^\wedge (y_n-\epsilon)\right )\\ &= \underset{all\ C \ge\alpha_n^\vee \geq 0,C \ge\alpha_n^\wedge \ge 0,\beta_n^\vee =C-\alpha_n^\vee,\beta_n^\wedge=C-\alpha_n^\wedge,\sum_{n=1}^{N}(\alpha _n^\wedge -\alpha _n^\vee)=0,\mathbf{w}=\sum_{n=1}^{N}(\alpha _n^\wedge-\alpha _n^\vee)\mathbf{z}_n}{max}\left (\underset{b,\mathbf{w},\boldsymbol\xi^\vee ,\boldsymbol\xi^\wedge}{min}\ -\frac{1}{2}\left \| \sum_{n=1}^{N}(\alpha _n^\wedge-\alpha _n^\vee)\mathbf{z}_n \right \|^2+\sum_{n=1}^{N}\alpha _n^\vee (-y_n-\epsilon)+\alpha _n^\wedge (y_n-\epsilon)\right )\\ [\because no\ b,\mathbf{w},\boldsymbol\xi^\vee ,\boldsymbol\xi^\wedge\ remove\ min] &= \underset{all\ C \ge\alpha_n^\vee \geq 0,C \ge\alpha_n^\wedge \ge 0,\beta_n^\vee =C-\alpha_n^\vee,\beta_n^\wedge=C-\alpha_n^\wedge,\sum_{n=1}^{N}(\alpha _n^\wedge -\alpha _n^\vee)=0,\mathbf{w}=\sum_{n=1}^{N}(\alpha _n^\wedge-\alpha _n^\vee)\mathbf{z}_n}{max}-\frac{1}{2}\left \| \sum_{n=1}^{N}(\alpha _n^\wedge-\alpha _n^\vee)\mathbf{z}_n \right \|^2+\sum_{n=1}^{N}(\alpha _n^\vee (-y_n-\epsilon)+\alpha _n^\wedge (y_n-\epsilon))\\ &= \underset{all\ C \ge\alpha_n^\vee \geq 0,C \ge\alpha_n^\wedge \ge 0,\beta_n^\vee =C-\alpha_n^\vee,\beta_n^\wedge=C-\alpha_n^\wedge,\sum_{n=1}^{N}(\alpha _n^\wedge -\alpha _n^\vee)=0,\mathbf{w}=\sum_{n=1}^{N}(\alpha _n^\wedge-\alpha _n^\vee)\mathbf{z}_n}{min}\frac{1}{2}\left \| \sum_{n=1}^{N}(\alpha _n^\wedge-\alpha _n^\vee)\mathbf{z}_n \right \|^2+\sum_{n=1}^{N}(\alpha _n^\vee (\epsilon+y_n)+\alpha _n^\wedge (\epsilon-y_n))\\ &= \underset{all\ C \ge\alpha_n^\vee \geq 0,C \ge\alpha_n^\wedge \ge 0,\beta_n^\vee =C-\alpha_n^\vee,\beta_n^\wedge=C-\alpha_n^\wedge,\sum_{n=1}^{N}(\alpha _n^\wedge -\alpha _n^\vee)=0,\mathbf{w}=\sum_{n=1}^{N}(\alpha _n^\wedge-\alpha _n^\vee)\mathbf{z}_n}{min}\frac{1}{2} \sum_{n=1}^{N}(\alpha _n^\wedge-\alpha _n^\vee)\mathbf{z}_n^T \sum_{n=1}^{N}(\alpha _n^\wedge-\alpha _n^\vee)\mathbf{z}_n +\sum_{n=1}^{N}(\alpha _n^\vee (\epsilon+y_n)+\alpha _n^\wedge (\epsilon-y_n))\\ &= \underset{all\ C \ge\alpha_n^\vee \geq 0,C \ge\alpha_n^\wedge \ge 0,\beta_n^\vee =C-\alpha_n^\vee,\beta_n^\wedge=C-\alpha_n^\wedge,\sum_{n=1}^{N}(\alpha _n^\wedge -\alpha _n^\vee)=0,\mathbf{w}=\sum_{n=1}^{N}(\alpha _n^\wedge-\alpha _n^\vee)\mathbf{z}_n}{min}\frac{1}{2} \sum_{n=1}^{N}\sum_{m=1}^{N}(\alpha _n^\wedge-\alpha _n^\vee)(\alpha _m^\wedge-\alpha _m^\vee)\mathbf{z}_n^T\mathbf{z}_m +\sum_{n=1}^{N}(\alpha _n^\vee (\epsilon+y_n)+\alpha _n^\wedge (\epsilon-y_n))\\ &= \underset{all\ C \ge\alpha_n^\vee \geq 0,C \ge\alpha_n^\wedge \ge 0,\beta_n^\vee =C-\alpha_n^\vee,\beta_n^\wedge=C-\alpha_n^\wedge,\sum_{n=1}^{N}(\alpha _n^\wedge -\alpha _n^\vee)=0,\mathbf{w}=\sum_{n=1}^{N}(\alpha _n^\wedge-\alpha _n^\vee)\mathbf{z}_n}{min}\frac{1}{2} \sum_{n=1}^{N}\sum_{m=1}^{N}(\alpha _n^\wedge-\alpha _n^\vee)(\alpha _m^\wedge-\alpha _m^\vee)\mathbf{K}(\mathbf{x}_n,\mathbf{x}_m) +\sum_{n=1}^{N}((\epsilon-y_n)\alpha _n^\wedge +(\epsilon+y_n)\alpha _n^\vee )\\ \end{align*} $$
將限制條件移出
$$ \begin{align*} \underset{\mathbf{\boldsymbol\alpha^\wedge,\boldsymbol\alpha^\vee }}{min}\ \ &\frac{1}{2}\sum_{n=1}^{N}\sum_{m=1}^{N}(\alpha_n^\wedge-\alpha_n^\vee)(\alpha_m^\wedge-\alpha_m^\vee)\mathbf{K}(\mathbf{x}_n,\mathbf{x}_m)+\sum_{n=1}^{N}((\epsilon -y_n)\alpha_n^\wedge+(\epsilon +y_n)\alpha_n^\vee)\\ s.t.\ \ &\sum_{n=1}^{N}(\alpha_n^\wedge-\alpha_n^\vee)=0\\ &0 \le \alpha_n^\wedge \le C,\ 0 \le \alpha_n^\vee \le C,\\ \end{align*} $$ 求 \(\alpha_n^\vee,\alpha_n^\wedge\) 共 \(2N\) 個變數
限制條件 \(\alpha_n^\vee,\alpha_n^\wedge\) 有 \(4N\) 個,加上 \(\sum_{n=1}^{N}(\alpha_n^\wedge-\alpha_n^\vee)=0\),共 \(4N+1\)
已知 \(\mathbf{w}=\sum_{n=1}^{N}(\alpha _n^\wedge-\alpha _n^\vee)\mathbf{z}_n\)
那如何得 \(b\) 呢?利用 KKT
$$ \begin{align*} \alpha _n^\vee (-y_n+\mathbf{w}^T\mathbf{z}_n+b-\epsilon-\xi_n^\vee)=0\\ \Rightarrow \alpha _n^\vee>0 \Rightarrow -y_n+\mathbf{w}^T\mathbf{z}_n+b-\epsilon-\xi_n^\vee=0\\ \beta_n^\vee=C-\alpha_n^\vee>0 \Rightarrow -\xi_n^\vee=0 \Rightarrow \alpha_n^\vee<C\\ \\\\ \alpha _n^\wedge (y_n-\mathbf{w}^T\mathbf{z}_n-b-\epsilon-\xi_n^\wedge)=0\\ \Rightarrow \alpha _n^\wedge >0 \Rightarrow y_n-\mathbf{w}^T\mathbf{z}_n-b-\epsilon-\xi_n^\wedge =0\\ \beta_n^\wedge =C-\alpha_n^\wedge >0 \Rightarrow -\xi_n^\wedge =0 \Rightarrow \alpha_n^\wedge< C \\ \end{align*} $$ 利用以上其中一組條件可得
$$ \begin{align*} 0&=-y_n+\mathbf{w}^T\mathbf{z}_n+b-\epsilon-\xi_n^\vee\\ b&=y_n-\mathbf{w}^T\mathbf{z}_n+\epsilon+\xi_n^\vee\\ \because \alpha_n^\vee<C\ \ b&=y_n-\mathbf{w}^T\mathbf{z}_n+\epsilon\\ \end{align*} $$ 或是 $$ \begin{align*} 0&=y_n-\mathbf{w}^T\mathbf{z}_n-b-\epsilon-\xi_n^\wedge\\ b&=y_n-\mathbf{w}^T\mathbf{z}_n-\epsilon-\xi_n^\wedge\\ \because \alpha_n^\wedge<C\ \ b&=y_n-\mathbf{w}^T\mathbf{z}_n-\epsilon\\ \end{align*} $$ 故
$$ C>\alpha_n^\vee>0\\ b=y_n-\mathbf{w}^T\mathbf{z}_n+\epsilon\\ \\ C>\alpha_n^\wedge>0\\ b=y_n-\mathbf{w}^T\mathbf{z}_n-\epsilon\\ $$ 而可以發現,當錯誤在 tube 內的話
首先重新定義 err 從 square regression 改為 tube regression

若超過時,則扣掉水管範圍部分,也就是 \(|s-y| > \epsilon\) 時,err=\(|s-y|-\epsilon\)
可得 \(err(y,s)=max(0,|s-y|-\epsilon)\)
如圖,可看到 err 在兩者接近 s 時,大約相同,遠離時 tube 成長幅度比較沒那麼劇烈


$$ \underset{\mathbf{w}}{min}\ \ \frac{\lambda}{N}\mathbf{w}^T\mathbf{w}+\frac{1}{N}\sum_{n=1}^{N}max(0,|\mathbf{w}^T\mathbf{z}_n-y_n|-\epsilon ) $$ 為了更接近標準的 SVM 定義,重新調整參數
$$ \begin{align*} &\underset{\mathbf{w}}{min}\ \ \frac{\lambda}{N}\mathbf{w}^T\mathbf{w}+\frac{1}{N}\sum_{n=1}^{N}max(0,|\mathbf{w}^T\mathbf{z}_n-y_n|-\epsilon ) \\ \Rightarrow\ \ &\underset{\mathbf{w}}{min}\ \ \frac{\lambda}{2N}\mathbf{w}^T\mathbf{w}+\frac{1}{2N}\sum_{n=1}^{N}max(0,|\mathbf{w}^T\mathbf{z}_n-y_n|-\epsilon ) \\ \because \lambda >0\Rightarrow\ \ &\underset{\mathbf{w}}{min}\ \ \frac{1}{2N}\mathbf{w}^T\mathbf{w}+\frac{1}{2N\lambda}\sum_{n=1}^{N}max(0,|\mathbf{w}^T\mathbf{z}_n-y_n|-\epsilon ) \\ \because N >0\Rightarrow\ \ &\underset{\mathbf{w}}{min}\ \ \frac{1}{2}\mathbf{w}^T\mathbf{w}+\frac{1}{2\lambda}\sum_{n=1}^{N}max(0,|\mathbf{w}^T\mathbf{z}_n-y_n|-\epsilon ) \\ \Rightarrow\ \ &\underset{\mathbf{w}}{min}\ \ \frac{1}{2}\mathbf{w}^T\mathbf{w}+C\sum_{n=1}^{N}max(0,|\mathbf{w}^T\mathbf{z}_n-y_n|-\epsilon ) \\ \Rightarrow\ \ &\underset{b,\mathbf{w}}{min}\ \ \frac{1}{2}\mathbf{w}^T\mathbf{w}+C\sum_{n=1}^{N}max(0,|\mathbf{w}^T\mathbf{z}_n+b-y_n|-\epsilon ) \\ \end{align*} $$ 最後加上 \(b\) 的原因,是為了更加符合標準的定義,且因為加上 \(b\) 但又對其最小化,不影響原先結果
用 \(\xi_n\) 表達錯誤,重新定義方程式,當 \(|\mathbf{w}^T\mathbf{z}_n+b-y_n|\le\epsilon\) 時,\(\xi_n=0\),不然就 \(\xi_n>0\)
$$ \begin{align*} &\underset{b,\mathbf{w}}{min}\ \ \frac{1}{2}\mathbf{w}^T\mathbf{w}+C\sum_{n=1}^{N}max(0,|\mathbf{w}^T\mathbf{z}_n+b-y_n|-\epsilon ) \\ \Rightarrow\ \ &\underset{b,\mathbf{w},\boldsymbol\xi}{min}\ \ \frac{1}{2}\mathbf{w}^T\mathbf{w}+C\sum_{n=1}^{N}\xi_n\\ &s.t.\ \ |\mathbf{w}^T\mathbf{z}_n+b-y_n|\le\epsilon+\xi_n\\ &\ \ \ \ \ \ \xi_n \ge 0\\ \end{align*} $$ 絕對值仍存在,還不是線性方程式,故再將之展開,並將 \(\xi_n\) 定義上下限
且將 \(|\mathbf{w}^T\mathbf{z}_n+b-y_n|\) 反向,符合常用定義
$$ \begin{align*} &\underset{b,\mathbf{w},\boldsymbol\xi}{min}\ \ \frac{1}{2}\mathbf{w}^T\mathbf{w}+C\sum_{n=1}^{N}\xi_n\\ &s.t.\ \ |\mathbf{w}^T\mathbf{z}_n+b-y_n|\le\epsilon+\xi_n\\ &\ \ \ \ \ \ \ \ \ \ \xi_n \ge 0\\ \Rightarrow\ \ &\underset{b,\mathbf{w},\boldsymbol\xi^\vee,\boldsymbol\xi^\wedge}{min}\ \ \frac{1}{2}\mathbf{w}^T\mathbf{w}+C\sum_{n=1}^{N}(\xi_n^\vee +\xi_n^\wedge) \\ &s.t.\ \ \ \ \ \ -\epsilon-\xi_n^\vee\le y_n-\mathbf{w}^T\mathbf{z}_n-b\le\epsilon+\xi_n^\wedge\\ &\ \ \ \ \ \ \ \ \ \ \ \ \ \ \xi_n^\vee \ge 0,\ \xi_n^\wedge \ge 0 \end{align*} $$ 故可得 primal,QP of \(\tilde{d}+1+N\) 個變數,\(2N+2N\) 個條件
但這還不是想要的,dual 又該如何得到呢?
利用 Lagrange multipliers,隱藏限制條件,此處將 \(\lambda _n\) 用 \(\alpha _n^\wedge\) & \(\alpha _n^\vee\) & \(\beta_n^\wedge\) & \(\beta_n^\vee\) 取代
$$ L(b,\mathbf{w},\boldsymbol\xi^\vee ,\boldsymbol\xi^\wedge,\boldsymbol\alpha^\vee,\boldsymbol\alpha^\wedge,\boldsymbol\beta^\vee,\boldsymbol\beta^\wedge)=\frac{1}{2}\mathbf{w}^T\mathbf{w}+C\cdot \sum_{n=1}^{N}(\xi _n^\vee +\xi _n^\wedge )+\sum_{n=1}^{N}\alpha _n^\vee (-y_n+\mathbf{w}^T\mathbf{z}_n+b-\epsilon-\xi_n^\vee)+\sum_{n=1}^{N}\alpha _n^\wedge (y_n-\mathbf{w}^T\mathbf{z}_n-b-\epsilon-\xi_n^\wedge)+\sum_{n=1}^{N}\beta_n^\wedge\cdot (-\xi_n^\wedge)+\sum_{n=1}^{N}\beta_n^\vee\cdot (-\xi_n^\vee) $$ 當 \(\underset{all\ \alpha_n^\vee \geq 0,\alpha_n^\wedge \ge 0,\beta_n^\vee \geq 0,\beta_n^\wedge\ge 0}{max}\ L(b,\mathbf{w},\boldsymbol\xi^\vee ,\boldsymbol\xi^\wedge,\boldsymbol\alpha^\vee,\boldsymbol\alpha^\wedge,\boldsymbol\beta^\vee,\boldsymbol\beta^\wedge)\) 會發現
- \((b,\mathbf{w},\boldsymbol\xi^\vee ,\boldsymbol\xi^\wedge)\) 違反限制條件時,會導致
- \(-y_n+\mathbf{w}^T\mathbf{z}_n+b-\epsilon-\xi_n^\vee>0\)
又因 \(L(b,\mathbf{w},\boldsymbol\xi^\vee ,\boldsymbol\xi^\wedge,\boldsymbol\alpha^\vee,\boldsymbol\alpha^\wedge,\boldsymbol\beta^\vee,\boldsymbol\beta^\wedge) \) 針對 \(\alpha _n ^\vee \) 取 max 的緣故,\(\alpha _n^\vee \) 越大越好 - \(y_n-\mathbf{w}^T\mathbf{z}_n-b-\epsilon-\xi_n^\wedge>0\)
又因 \(L(b,\mathbf{w},\boldsymbol\xi^\vee ,\boldsymbol\xi^\wedge,\boldsymbol\alpha^\vee,\boldsymbol\alpha^\wedge,\boldsymbol\beta^\vee,\boldsymbol\beta^\wedge) \) 針對 \(\alpha _n ^\wedge \) 取 max 的緣故,\(\alpha _n^\wedge \) 越大越好 - \(-\xi _n^\vee>0\)
又因 \(L(b,\mathbf{w},\boldsymbol\xi^\vee ,\boldsymbol\xi^\wedge,\boldsymbol\alpha^\vee,\boldsymbol\alpha^\wedge,\boldsymbol\beta^\vee,\boldsymbol\beta^\wedge) \) 針對 \(\beta _n^\vee \) 取 max 的緣故,\(\beta _n^\vee \) 越大越好 - \(-\xi _n^\wedge>0\)
又因 \(L(b,\mathbf{w},\boldsymbol\xi^\vee ,\boldsymbol\xi^\wedge,\boldsymbol\alpha^\vee,\boldsymbol\alpha^\wedge,\boldsymbol\beta^\vee,\boldsymbol\beta^\wedge) \) 針對 \(\beta _n^\wedge \) 取 max 的緣故,\(\beta _n^\wedge \) 越大越好 - 使得 \(L(b,\mathbf{w},\boldsymbol\xi^\vee ,\boldsymbol\xi^\wedge,\boldsymbol\alpha^\vee,\boldsymbol\alpha^\wedge,\boldsymbol\beta^\vee,\boldsymbol\beta^\wedge)\rightarrow \infty \)
- \((b,\mathbf{w},\boldsymbol\xi^\vee ,\boldsymbol\xi^\wedge)\) 符合限制條件時,會導致
- \(-y_n+\mathbf{w}^T\mathbf{z}_n+b-\epsilon-\xi_n^\vee \leq 0\)
又因 \(L(b,\mathbf{w},\boldsymbol\xi^\vee ,\boldsymbol\xi^\wedge,\boldsymbol\alpha^\vee,\boldsymbol\alpha^\wedge,\boldsymbol\beta^\vee,\boldsymbol\beta^\wedge) \) 針對 \(\alpha _n^\vee \) 取 max 的緣故,\(\alpha _n^\vee \) 與 \(-y_n+\mathbf{w}^T\mathbf{z}_n+b-\epsilon-\xi_n^\vee\) 兩者至少有一個必須為 0 - \(y_n-\mathbf{w}^T\mathbf{z}_n-b-\epsilon-\xi_n^\wedge \leq 0\)
又因 \(L(b,\mathbf{w},\boldsymbol\xi^\vee ,\boldsymbol\xi^\wedge,\boldsymbol\alpha^\vee,\boldsymbol\alpha^\wedge,\boldsymbol\beta^\vee,\boldsymbol\beta^\wedge) \) 針對 \(\alpha _n^\wedge \) 取 max 的緣故,\(\alpha _n^\wedge \) 與 \(y_n-\mathbf{w}^T\mathbf{z}_n-b-\epsilon-\xi_n^\wedge\) 兩者至少有一個必須為 0 - \(-\xi _n^\vee \leq 0\)
又因 \(L(b,\mathbf{w},\boldsymbol\xi^\vee ,\boldsymbol\xi^\wedge,\boldsymbol\alpha^\vee,\boldsymbol\alpha^\wedge,\boldsymbol\beta^\vee,\boldsymbol\beta^\wedge) \) 針對 \(\beta _n^\vee \) 取 max 的緣故,\(\beta _n^\vee \) 與 \(- \xi_n^\vee\) 兩者至少有一個必須為 0 - \(-\xi _n^\wedge \leq 0\)
又因 \(L(b,\mathbf{w},\boldsymbol\xi^\vee ,\boldsymbol\xi^\wedge,\boldsymbol\alpha^\vee,\boldsymbol\alpha^\wedge,\boldsymbol\beta^\vee,\boldsymbol\beta^\wedge) \) 針對 \(\beta _n^\wedge \) 取 max 的緣故,\(\beta _n^\wedge \) 與 \(- \xi_n^\wedge\) 兩者至少有一個必須為 0 - 使得 \(L(b,\mathbf{w},\boldsymbol\xi^\vee ,\boldsymbol\xi^\wedge,\boldsymbol\alpha^\vee,\boldsymbol\alpha^\wedge,\boldsymbol\beta^\vee,\boldsymbol\beta^\wedge)\rightarrow \frac{1}{2}\mathbf{w}^T\mathbf{w} \)
$$ SVM\equiv \underset{b,\mathbf{w},\boldsymbol\xi^\vee ,\boldsymbol\xi^\wedge}{min}\left (\underset{all\ \alpha_n^\vee \geq 0,\alpha_n^\wedge \ge 0,\beta_n^\vee \geq 0,\beta_n^\wedge\ge 0}{max}\ L(b,\mathbf{w},\boldsymbol\xi^\vee ,\boldsymbol\xi^\wedge,\boldsymbol\alpha^\vee,\boldsymbol\alpha^\wedge,\boldsymbol\beta^\vee,\boldsymbol\beta^\wedge) \right )=\underset{b,\mathbf{w},\boldsymbol\xi^\vee ,\boldsymbol\xi^\wedge}{min}\left (\infty\ if\ violate;\frac{1}{2}\mathbf{w}^T\mathbf{w}\ if\ feasible \right ) $$
此時 \((b,\mathbf{w},\boldsymbol\xi^\vee ,\boldsymbol\xi^\wedge)\) 仍在式子最外面,如何把它跟裡面的 \(\alpha _n^\wedge,\alpha _n^\vee,\beta _n^\wedge,\beta _n^\vee \) 交換呢?
這樣才能初步得到 4N 個變數的式子
任取一個 \(\boldsymbol{\alpha}'^\vee,\boldsymbol{\alpha}'^\wedge,\boldsymbol{\beta}'^\vee,\boldsymbol{\beta}'^\wedge\) with \({\alpha}'^\vee_n \ge 0,{\alpha}'^\wedge_n \ge 0,{\beta}'^\vee_n \ge 0,{\beta}'^\wedge_n \ge 0\)
因取 max 一定比任意還大,可得下式
\(\underset{b,\mathbf{w},\boldsymbol\xi^\vee ,\boldsymbol\xi^\wedge}{min}\left (\underset{all\ \alpha_n^\vee \geq 0,\alpha_n^\wedge \ge 0,\beta_n^\vee \geq 0,\beta_n^\wedge\ge 0}{max}\ L(b,\mathbf{w},\boldsymbol\xi^\vee ,\boldsymbol\xi^\wedge,\boldsymbol\alpha^\vee,\boldsymbol\alpha^\wedge,\boldsymbol\beta^\vee,\boldsymbol\beta^\wedge) \right ) \geq \underset{b,\mathbf{w},\boldsymbol\xi^\vee ,\boldsymbol\xi^\wedge}{min}\ L(b,\mathbf{w},\boldsymbol\xi^\vee ,\boldsymbol\xi^\wedge,\boldsymbol{\alpha}'^\vee,\boldsymbol{\alpha}'^\wedge,\boldsymbol{\beta}'^\vee,\boldsymbol{\beta}'^\wedge)\)
那如果對 \(\boldsymbol{\alpha}'^\vee \ge 0,\boldsymbol{\alpha}'^\wedge \ge 0,\boldsymbol{\beta}'^\vee \ge 0,\boldsymbol{\beta}'^\wedge \ge 0\) 取 max,也不影響此等式,如下
\(\underset{b,\mathbf{w},\boldsymbol\xi^\vee ,\boldsymbol\xi^\wedge}{min}\left (\underset{all\ \alpha_n^\vee \geq 0,\alpha_n^\wedge \ge 0,\beta_n^\vee \geq 0,\beta_n^\wedge\ge 0}{max}\ L(b,\mathbf{w},\boldsymbol\xi^\vee ,\boldsymbol\xi^\wedge,\boldsymbol\alpha^\vee,\boldsymbol\alpha^\wedge,\boldsymbol\beta^\vee,\boldsymbol\beta^\wedge) \right ) \geq \underset{Lagrange\ dual\ problem}{\underbrace{\underset{all\ \boldsymbol{\alpha}'^\vee \ge 0,\boldsymbol{\alpha}'^\wedge \ge 0,\boldsymbol{\beta}'^\vee \ge 0,\boldsymbol{\beta}'^\wedge \ge 0}{max}\left (\underset{b,\mathbf{w},\boldsymbol\xi^\vee ,\boldsymbol\xi^\wedge}{min}\ L(b,\mathbf{w},\boldsymbol\xi^\vee ,\boldsymbol\xi^\wedge,\boldsymbol{\alpha}'^\vee,\boldsymbol{\alpha}'^\wedge,\boldsymbol{\beta}'^\vee,\boldsymbol{\beta}'^\wedge) \right )\overset{\boldsymbol{\alpha}'^\vee=\boldsymbol\alpha^\vee,\boldsymbol{\alpha}'^\wedge=\boldsymbol\alpha^\wedge,\boldsymbol{\beta}'^\vee=\boldsymbol\beta^\vee,\boldsymbol{\beta}'^\wedge=\boldsymbol\beta^\wedge}{\rightarrow} \underset{all\ \alpha_n^\vee \geq 0,\alpha_n^\wedge \ge 0,\beta_n^\vee \geq 0,\beta_n^\wedge\ge 0}{max}\left (\underset{b,\mathbf{w},\boldsymbol\xi^\vee ,\boldsymbol\xi^\wedge}{min}\ L(b,\mathbf{w},\boldsymbol\xi^\vee ,\boldsymbol\xi^\wedge,\boldsymbol\alpha^\vee,\boldsymbol\alpha^\wedge,\boldsymbol\beta^\vee,\boldsymbol\beta^\wedge) \right )}}\)
比較直覺的想法,就像是「從最大的一群中取最小」一定 \(\ge\) 「從最小的一群中取最大」
$$ \underset{original(primal))\ SVM}{\underbrace{\underset{b,\mathbf{w},\boldsymbol\xi^\vee ,\boldsymbol\xi^\wedge}{min}\left (\underset{all\ \alpha_n^\vee \geq 0,\alpha_n^\wedge \ge 0,\beta_n^\vee \geq 0,\beta_n^\wedge\ge 0}{max}\ L(b,\mathbf{w},\boldsymbol\xi^\vee ,\boldsymbol\xi^\wedge,\boldsymbol\alpha^\vee,\boldsymbol\alpha^\wedge,\boldsymbol\beta^\vee,\boldsymbol\beta^\wedge) \right )}} \geq \underset{Lagrange\ dual}{\underbrace{ \underset{all\ \alpha_n^\vee \geq 0,\alpha_n^\wedge \ge 0,\beta_n^\vee \geq 0,\beta_n^\wedge\ge 0}{max}\left (\underset{b,\mathbf{w},\boldsymbol\xi^\vee ,\boldsymbol\xi^\wedge}{min}\ L(b,\mathbf{w},\boldsymbol\xi^\vee ,\boldsymbol\xi^\wedge,\boldsymbol\alpha^\vee,\boldsymbol\alpha^\wedge,\boldsymbol\beta^\vee,\boldsymbol\beta^\wedge) \right )}} $$ 目前的關係稱作 \(\ge\) weak duality
但這還不夠,最好是 \(=\) strong duality,才能初步得到 4N 個變數的式子
幸運的是,在 QP 中,只要滿足以下條件,便是 strong duality
- convex primal (原來的問題為 convex)
- feasible primal (原來的問題有解的,也就是線性可分)
- linear constraints (限制條件為線性的)
$$ \underset{all\ \alpha_n^\vee \geq 0,\alpha_n^\wedge \ge 0,\beta_n^\vee \geq 0,\beta_n^\wedge\ge 0}{max}\left (\underset{b,\mathbf{w},\boldsymbol\xi^\vee ,\boldsymbol\xi^\wedge}{min}\ \underset{L(b,\mathbf{w},\boldsymbol\xi^\vee ,\boldsymbol\xi^\wedge,\boldsymbol\alpha^\vee,\boldsymbol\alpha^\wedge,\boldsymbol\beta^\vee,\boldsymbol\beta^\wedge)}{\underbrace{\frac{1}{2}\mathbf{w}^T\mathbf{w}+C\cdot \sum_{n=1}^{N}(\xi _n^\vee +\xi _n^\wedge )+\sum_{n=1}^{N}\alpha _n^\vee (-y_n+\mathbf{w}^T\mathbf{z}_n+b-\epsilon-\xi_n^\vee)+\sum_{n=1}^{N}\alpha _n^\wedge (y_n-\mathbf{w}^T\mathbf{z}_n-b-\epsilon-\xi_n^\wedge)+\sum_{n=1}^{N}\beta_n^\wedge\cdot (-\xi_n^\wedge)+\sum_{n=1}^{N}\beta_n^\vee\cdot (-\xi_n^\vee)}}\right ) $$
但如何把內部的 \((b,\mathbf{w},\boldsymbol\xi^\vee ,\boldsymbol\xi^\wedge)\) 拿掉呢?
內部的問題,當最佳化時,必定符合
$$ \begin{align*} \frac{\partial L(b,\mathbf{w},\boldsymbol\xi^\vee ,\boldsymbol\xi^\wedge,\boldsymbol\alpha^\vee,\boldsymbol\alpha^\wedge,\boldsymbol\beta^\vee,\boldsymbol\beta^\wedge)}{\partial b}&=0=\sum_{n=1}^{N}(\alpha_n^\vee-\alpha_n^\wedge) \Rightarrow \sum_{n=1}^{N}(\alpha_n^\wedge-\alpha_n^\vee)=0\\ \frac{\partial L(b,\mathbf{w},\boldsymbol\xi^\vee ,\boldsymbol\xi^\wedge,\boldsymbol\alpha^\vee,\boldsymbol\alpha^\wedge,\boldsymbol\beta^\vee,\boldsymbol\beta^\wedge)}{\partial \mathbf{w}}&=\mathbf{0}=\mathbf{w}+\sum_{n=1}^{N}\alpha _n^\vee\mathbf{z}_n-\sum_{n=1}^{N}\alpha _n^\wedge\mathbf{z}_n \Rightarrow \mathbf{w}=\sum_{n=1}^{N}\underset{\beta_n}{\underbrace{(\alpha _n^\wedge-\alpha _n^\vee)}}\mathbf{z}_n\\ \frac{\partial L(b,\mathbf{w},\boldsymbol\xi^\vee ,\boldsymbol\xi^\wedge,\boldsymbol\alpha^\vee,\boldsymbol\alpha^\wedge,\boldsymbol\beta^\vee,\boldsymbol\beta^\wedge)}{\partial \xi^\vee}&=0=C-\alpha _n^\vee-\beta _n^\vee \Rightarrow \beta_n^\vee=C-\alpha_n^\vee\\ \frac{\partial L(b,\mathbf{w},\boldsymbol\xi^\vee ,\boldsymbol\xi^\wedge,\boldsymbol\alpha^\vee,\boldsymbol\alpha^\wedge,\boldsymbol\beta^\vee,\boldsymbol\beta^\wedge)}{\partial \xi^\wedge}&=0=C-\alpha _n^\wedge-\beta _n^\wedge \Rightarrow \beta_n^\wedge=C-\alpha_n^\wedge\\ \end{align*} $$ 從以上的這些條件,可得
$$ \begin{align*} dual&=\underset{all\ \alpha_n^\vee \geq 0,\alpha_n^\wedge \ge 0,\beta_n^\vee \geq 0,\beta_n^\wedge\ge 0}{max}\left (\underset{b,\mathbf{w},\boldsymbol\xi^\vee ,\boldsymbol\xi^\wedge}{min}\ \frac{1}{2}\mathbf{w}^T\mathbf{w}+C\cdot \sum_{n=1}^{N}(\xi _n^\vee +\xi _n^\wedge )+\sum_{n=1}^{N}\alpha _n^\vee (-y_n+\mathbf{w}^T\mathbf{z}_n+b-\epsilon-\xi_n^\vee)+\sum_{n=1}^{N}\alpha _n^\wedge (y_n-\mathbf{w}^T\mathbf{z}_n-b-\epsilon-\xi_n^\wedge)+\sum_{n=1}^{N}\beta_n^\wedge\cdot (-\xi_n^\wedge)+\sum_{n=1}^{N}\beta_n^\vee\cdot (-\xi_n^\vee)\right ) \\ &=\underset{all\ \alpha_n^\vee \geq 0,\alpha_n^\wedge \ge 0,\beta_n^\vee \geq 0,\beta_n^\wedge\ge 0}{max}\left (\underset{b,\mathbf{w},\boldsymbol\xi^\vee ,\boldsymbol\xi^\wedge}{min}\ \frac{1}{2}\mathbf{w}^T\mathbf{w}+C\cdot \sum_{n=1}^{N}(\xi _n^\vee +\xi _n^\wedge)+\sum_{n=1}^{N}(\alpha _n^\vee\cdot - \xi_n^\vee+\alpha _n^\wedge\cdot - \xi_n^\wedge) +\sum_{n=1}^{N}\alpha _n^\vee (-y_n+\mathbf{w}^T\mathbf{z}_n+b-\epsilon)+\sum_{n=1}^{N}\alpha _n^\wedge (y_n-\mathbf{w}^T\mathbf{z}_n-b-\epsilon)+\sum_{n=1}^{N}\beta_n^\wedge\cdot (-\xi_n^\wedge)+\sum_{n=1}^{N}\beta_n^\vee\cdot (-\xi_n^\vee)\right )\\ &=\underset{all\ \alpha_n^\vee \geq 0,\alpha_n^\wedge \ge 0,\beta_n^\vee =C-\alpha_n^\vee,\beta_n^\wedge=C-\alpha_n^\wedge}{max}\left (\underset{b,\mathbf{w},\boldsymbol\xi^\vee ,\boldsymbol\xi^\wedge}{min}\ \frac{1}{2}\mathbf{w}^T\mathbf{w}+\sum_{n=1}^{N}((C-\alpha _n^\vee-\beta_n^\vee)\xi _n^\vee +(C-\alpha _n^\wedge-\beta_n^\wedge)\xi _n^\wedge)+\sum_{n=1}^{N}\alpha _n^\vee (-y_n+\mathbf{w}^T\mathbf{z}_n+b-\epsilon)+\sum_{n=1}^{N}\alpha _n^\wedge (y_n-\mathbf{w}^T\mathbf{z}_n-b-\epsilon)\right )\\ [\because 0=C-\alpha _n^\wedge-\beta _n^\wedge,0=C-\alpha _n^\vee-\beta _n^\vee]&=\underset{all\ \alpha_n^\vee \geq 0,\alpha_n^\wedge \ge 0,\beta_n^\vee \geq 0,\beta_n^\wedge\ge 0}{max}\left (\underset{b,\mathbf{w},\boldsymbol\xi^\vee ,\boldsymbol\xi^\wedge}{min}\ \frac{1}{2}\mathbf{w}^T\mathbf{w}+\sum_{n=1}^{N}\alpha _n^\vee (-y_n+\mathbf{w}^T\mathbf{z}_n+b-\epsilon)+\sum_{n=1}^{N}\alpha _n^\wedge (y_n-\mathbf{w}^T\mathbf{z}_n-b-\epsilon)\right )\\ [\because \beta _n^\wedge \ge 0\Rightarrow \alpha_n^\wedge \le C,\beta _n^\vee \ge 0\Rightarrow \alpha_n^\vee \le C]&=\underset{all\ C \ge\alpha_n^\vee \geq 0,C \ge\alpha_n^\wedge \ge 0,\beta_n^\vee =C-\alpha_n^\vee,\beta_n^\wedge=C-\alpha_n^\wedge}{max}\left (\underset{b,\mathbf{w},\boldsymbol\xi^\vee ,\boldsymbol\xi^\wedge}{min}\ \frac{1}{2}\mathbf{w}^T\mathbf{w}+\sum_{n=1}^{N}\alpha _n^\vee (-y_n+\mathbf{w}^T\mathbf{z}_n+b-\epsilon)+\sum_{n=1}^{N}\alpha _n^\wedge (y_n-\mathbf{w}^T\mathbf{z}_n-b-\epsilon)\right )\\ &=\underset{all\ C \ge\alpha_n^\vee \geq 0,C \ge\alpha_n^\wedge \ge 0,\beta_n^\vee =C-\alpha_n^\vee,\beta_n^\wedge=C-\alpha_n^\wedge}{max}\left (\underset{b,\mathbf{w},\boldsymbol\xi^\vee ,\boldsymbol\xi^\wedge}{min}\ \frac{1}{2}\mathbf{w}^T\mathbf{w}+\sum_{n=1}^{N}(\alpha _n^\wedge -\alpha _n^\vee) (-b)+\sum_{n=1}^{N}\alpha _n^\vee (-y_n+\mathbf{w}^T\mathbf{z}_n-\epsilon)+\sum_{n=1}^{N}\alpha _n^\wedge (y_n-\mathbf{w}^T\mathbf{z}_n-\epsilon)\right )\\ [\because \sum_{n=1}^{N}(\alpha _n^\wedge -\alpha _n^\vee)=0] &= \underset{all\ C \ge\alpha_n^\vee \geq 0,C \ge\alpha_n^\wedge \ge 0,\beta_n^\vee =C-\alpha_n^\vee,\beta_n^\wedge=C-\alpha_n^\wedge,\sum_{n=1}^{N}(\alpha _n^\wedge -\alpha _n^\vee)=0}{max}\left (\underset{b,\mathbf{w},\boldsymbol\xi^\vee ,\boldsymbol\xi^\wedge}{min}\ \frac{1}{2}\mathbf{w}^T\mathbf{w}+\sum_{n=1}^{N}\alpha _n^\vee (-y_n+\mathbf{w}^T\mathbf{z}_n-\epsilon)+\sum_{n=1}^{N}\alpha _n^\wedge (y_n-\mathbf{w}^T\mathbf{z}_n-\epsilon)\right )\\ &= \underset{all\ C \ge\alpha_n^\vee \geq 0,C \ge\alpha_n^\wedge \ge 0,\beta_n^\vee =C-\alpha_n^\vee,\beta_n^\wedge=C-\alpha_n^\wedge,\sum_{n=1}^{N}(\alpha _n^\wedge -\alpha _n^\vee)=0}{max}\left (\underset{b,\mathbf{w},\boldsymbol\xi^\vee ,\boldsymbol\xi^\wedge}{min}\ \frac{1}{2}\mathbf{w}^T\mathbf{w}+\sum_{n=1}^{N}(\alpha _n^\wedge-\alpha _n^\vee)(-\mathbf{w}^T\mathbf{z}_n)+\sum_{n=1}^{N}\alpha _n^\vee (-y_n-\epsilon)+\sum_{n=1}^{N}\alpha _n^\wedge (y_n-\epsilon)\right )\\ &= \underset{all\ C \ge\alpha_n^\vee \geq 0,C \ge\alpha_n^\wedge \ge 0,\beta_n^\vee =C-\alpha_n^\vee,\beta_n^\wedge=C-\alpha_n^\wedge,\sum_{n=1}^{N}(\alpha _n^\wedge -\alpha _n^\vee)=0}{max}\left (\underset{b,\mathbf{w},\boldsymbol\xi^\vee ,\boldsymbol\xi^\wedge}{min}\ \frac{1}{2}\mathbf{w}^T\mathbf{w}+\sum_{n=1}^{N}-\mathbf{w}^T(\alpha _n^\wedge-\alpha _n^\vee)\mathbf{z}_n+\sum_{n=1}^{N}\alpha _n^\vee (-y_n-\epsilon)+\sum_{n=1}^{N}\alpha _n^\wedge (y_n-\epsilon)\right )\\ \end{align*} $$ $$ \begin{align*} [\because \mathbf{w}=\sum_{n=1}^{N}(\alpha _n^\wedge-\alpha _n^\vee)\mathbf{z}_n] &= \underset{all\ C \ge\alpha_n^\vee \geq 0,C \ge\alpha_n^\wedge \ge 0,\beta_n^\vee =C-\alpha_n^\vee,\beta_n^\wedge=C-\alpha_n^\wedge,\sum_{n=1}^{N}(\alpha _n^\wedge -\alpha _n^\vee)=0,\mathbf{w}=\sum_{n=1}^{N}(\alpha _n^\wedge-\alpha _n^\vee)\mathbf{z}_n}{max}\left (\underset{b,\mathbf{w},\boldsymbol\xi^\vee ,\boldsymbol\xi^\wedge}{min}\ \frac{1}{2}\mathbf{w}^T\mathbf{w}-\mathbf{w}^T\mathbf{w}+\sum_{n=1}^{N}\alpha _n^\vee (-y_n-\epsilon)+\sum_{n=1}^{N}\alpha _n^\wedge (y_n-\epsilon)\right )\\ &= \underset{all\ C \ge\alpha_n^\vee \geq 0,C \ge\alpha_n^\wedge \ge 0,\beta_n^\vee =C-\alpha_n^\vee,\beta_n^\wedge=C-\alpha_n^\wedge,\sum_{n=1}^{N}(\alpha _n^\wedge -\alpha _n^\vee)=0,\mathbf{w}=\sum_{n=1}^{N}(\alpha _n^\wedge-\alpha _n^\vee)\mathbf{z}_n}{max}\left (\underset{b,\mathbf{w},\boldsymbol\xi^\vee ,\boldsymbol\xi^\wedge}{min}\ -\frac{1}{2}\mathbf{w}^T\mathbf{w}+\sum_{n=1}^{N}\alpha _n^\vee (-y_n-\epsilon)+\alpha _n^\wedge (y_n-\epsilon)\right )\\ &= \underset{all\ C \ge\alpha_n^\vee \geq 0,C \ge\alpha_n^\wedge \ge 0,\beta_n^\vee =C-\alpha_n^\vee,\beta_n^\wedge=C-\alpha_n^\wedge,\sum_{n=1}^{N}(\alpha _n^\wedge -\alpha _n^\vee)=0,\mathbf{w}=\sum_{n=1}^{N}(\alpha _n^\wedge-\alpha _n^\vee)\mathbf{z}_n}{max}\left (\underset{b,\mathbf{w},\boldsymbol\xi^\vee ,\boldsymbol\xi^\wedge}{min}\ -\frac{1}{2}\left \| \sum_{n=1}^{N}(\alpha _n^\wedge-\alpha _n^\vee)\mathbf{z}_n \right \|^2+\sum_{n=1}^{N}\alpha _n^\vee (-y_n-\epsilon)+\alpha _n^\wedge (y_n-\epsilon)\right )\\ [\because no\ b,\mathbf{w},\boldsymbol\xi^\vee ,\boldsymbol\xi^\wedge\ remove\ min] &= \underset{all\ C \ge\alpha_n^\vee \geq 0,C \ge\alpha_n^\wedge \ge 0,\beta_n^\vee =C-\alpha_n^\vee,\beta_n^\wedge=C-\alpha_n^\wedge,\sum_{n=1}^{N}(\alpha _n^\wedge -\alpha _n^\vee)=0,\mathbf{w}=\sum_{n=1}^{N}(\alpha _n^\wedge-\alpha _n^\vee)\mathbf{z}_n}{max}-\frac{1}{2}\left \| \sum_{n=1}^{N}(\alpha _n^\wedge-\alpha _n^\vee)\mathbf{z}_n \right \|^2+\sum_{n=1}^{N}(\alpha _n^\vee (-y_n-\epsilon)+\alpha _n^\wedge (y_n-\epsilon))\\ &= \underset{all\ C \ge\alpha_n^\vee \geq 0,C \ge\alpha_n^\wedge \ge 0,\beta_n^\vee =C-\alpha_n^\vee,\beta_n^\wedge=C-\alpha_n^\wedge,\sum_{n=1}^{N}(\alpha _n^\wedge -\alpha _n^\vee)=0,\mathbf{w}=\sum_{n=1}^{N}(\alpha _n^\wedge-\alpha _n^\vee)\mathbf{z}_n}{min}\frac{1}{2}\left \| \sum_{n=1}^{N}(\alpha _n^\wedge-\alpha _n^\vee)\mathbf{z}_n \right \|^2+\sum_{n=1}^{N}(\alpha _n^\vee (\epsilon+y_n)+\alpha _n^\wedge (\epsilon-y_n))\\ &= \underset{all\ C \ge\alpha_n^\vee \geq 0,C \ge\alpha_n^\wedge \ge 0,\beta_n^\vee =C-\alpha_n^\vee,\beta_n^\wedge=C-\alpha_n^\wedge,\sum_{n=1}^{N}(\alpha _n^\wedge -\alpha _n^\vee)=0,\mathbf{w}=\sum_{n=1}^{N}(\alpha _n^\wedge-\alpha _n^\vee)\mathbf{z}_n}{min}\frac{1}{2} \sum_{n=1}^{N}(\alpha _n^\wedge-\alpha _n^\vee)\mathbf{z}_n^T \sum_{n=1}^{N}(\alpha _n^\wedge-\alpha _n^\vee)\mathbf{z}_n +\sum_{n=1}^{N}(\alpha _n^\vee (\epsilon+y_n)+\alpha _n^\wedge (\epsilon-y_n))\\ &= \underset{all\ C \ge\alpha_n^\vee \geq 0,C \ge\alpha_n^\wedge \ge 0,\beta_n^\vee =C-\alpha_n^\vee,\beta_n^\wedge=C-\alpha_n^\wedge,\sum_{n=1}^{N}(\alpha _n^\wedge -\alpha _n^\vee)=0,\mathbf{w}=\sum_{n=1}^{N}(\alpha _n^\wedge-\alpha _n^\vee)\mathbf{z}_n}{min}\frac{1}{2} \sum_{n=1}^{N}\sum_{m=1}^{N}(\alpha _n^\wedge-\alpha _n^\vee)(\alpha _m^\wedge-\alpha _m^\vee)\mathbf{z}_n^T\mathbf{z}_m +\sum_{n=1}^{N}(\alpha _n^\vee (\epsilon+y_n)+\alpha _n^\wedge (\epsilon-y_n))\\ &= \underset{all\ C \ge\alpha_n^\vee \geq 0,C \ge\alpha_n^\wedge \ge 0,\beta_n^\vee =C-\alpha_n^\vee,\beta_n^\wedge=C-\alpha_n^\wedge,\sum_{n=1}^{N}(\alpha _n^\wedge -\alpha _n^\vee)=0,\mathbf{w}=\sum_{n=1}^{N}(\alpha _n^\wedge-\alpha _n^\vee)\mathbf{z}_n}{min}\frac{1}{2} \sum_{n=1}^{N}\sum_{m=1}^{N}(\alpha _n^\wedge-\alpha _n^\vee)(\alpha _m^\wedge-\alpha _m^\vee)\mathbf{K}(\mathbf{x}_n,\mathbf{x}_m) +\sum_{n=1}^{N}((\epsilon-y_n)\alpha _n^\wedge +(\epsilon+y_n)\alpha _n^\vee )\\ \end{align*} $$
將限制條件移出
- \(\mathbf{w}=\sum_{n=1}^{N}(\alpha _n^\wedge-\alpha _n^\vee)\mathbf{z}_n\) 只是求 \(\mathbf{w}\) 並不限制 \(\boldsymbol\alpha^\vee,\boldsymbol\alpha^\wedge\)
- \(\beta_n^\vee =C-\alpha_n^\vee,\beta_n^\wedge=C-\alpha_n^\wedge\) 只是求 \(\beta_n^\vee, \beta_n^\wedge\) 並不限制 \(\boldsymbol\alpha^\vee,\boldsymbol\alpha^\wedge\)
$$ \begin{align*} \underset{\mathbf{\boldsymbol\alpha^\wedge,\boldsymbol\alpha^\vee }}{min}\ \ &\frac{1}{2}\sum_{n=1}^{N}\sum_{m=1}^{N}(\alpha_n^\wedge-\alpha_n^\vee)(\alpha_m^\wedge-\alpha_m^\vee)\mathbf{K}(\mathbf{x}_n,\mathbf{x}_m)+\sum_{n=1}^{N}((\epsilon -y_n)\alpha_n^\wedge+(\epsilon +y_n)\alpha_n^\vee)\\ s.t.\ \ &\sum_{n=1}^{N}(\alpha_n^\wedge-\alpha_n^\vee)=0\\ &0 \le \alpha_n^\wedge \le C,\ 0 \le \alpha_n^\vee \le C,\\ \end{align*} $$ 求 \(\alpha_n^\vee,\alpha_n^\wedge\) 共 \(2N\) 個變數
限制條件 \(\alpha_n^\vee,\alpha_n^\wedge\) 有 \(4N\) 個,加上 \(\sum_{n=1}^{N}(\alpha_n^\wedge-\alpha_n^\vee)=0\),共 \(4N+1\)
已知 \(\mathbf{w}=\sum_{n=1}^{N}(\alpha _n^\wedge-\alpha _n^\vee)\mathbf{z}_n\)
那如何得 \(b\) 呢?利用 KKT
$$ \begin{align*} \alpha _n^\vee (-y_n+\mathbf{w}^T\mathbf{z}_n+b-\epsilon-\xi_n^\vee)=0\\ \Rightarrow \alpha _n^\vee>0 \Rightarrow -y_n+\mathbf{w}^T\mathbf{z}_n+b-\epsilon-\xi_n^\vee=0\\ \beta_n^\vee=C-\alpha_n^\vee>0 \Rightarrow -\xi_n^\vee=0 \Rightarrow \alpha_n^\vee<C\\ \\\\ \alpha _n^\wedge (y_n-\mathbf{w}^T\mathbf{z}_n-b-\epsilon-\xi_n^\wedge)=0\\ \Rightarrow \alpha _n^\wedge >0 \Rightarrow y_n-\mathbf{w}^T\mathbf{z}_n-b-\epsilon-\xi_n^\wedge =0\\ \beta_n^\wedge =C-\alpha_n^\wedge >0 \Rightarrow -\xi_n^\wedge =0 \Rightarrow \alpha_n^\wedge< C \\ \end{align*} $$ 利用以上其中一組條件可得
$$ \begin{align*} 0&=-y_n+\mathbf{w}^T\mathbf{z}_n+b-\epsilon-\xi_n^\vee\\ b&=y_n-\mathbf{w}^T\mathbf{z}_n+\epsilon+\xi_n^\vee\\ \because \alpha_n^\vee<C\ \ b&=y_n-\mathbf{w}^T\mathbf{z}_n+\epsilon\\ \end{align*} $$ 或是 $$ \begin{align*} 0&=y_n-\mathbf{w}^T\mathbf{z}_n-b-\epsilon-\xi_n^\wedge\\ b&=y_n-\mathbf{w}^T\mathbf{z}_n-\epsilon-\xi_n^\wedge\\ \because \alpha_n^\wedge<C\ \ b&=y_n-\mathbf{w}^T\mathbf{z}_n-\epsilon\\ \end{align*} $$ 故
$$ C>\alpha_n^\vee>0\\ b=y_n-\mathbf{w}^T\mathbf{z}_n+\epsilon\\ \\ C>\alpha_n^\wedge>0\\ b=y_n-\mathbf{w}^T\mathbf{z}_n-\epsilon\\ $$ 而可以發現,當錯誤在 tube 內的話
- 若為下限處
\(-\xi _n^\vee = 0\) & \(-y_n+\mathbf{w}^T\mathbf{z}_n+b-\epsilon-\xi_n^\vee < 0\)
故 \(\alpha _n^\vee =0\) - 若為上限處
\(-\xi _n^\wedge = 0\) & \(y_n-\mathbf{w}^T\mathbf{z}_n-b-\epsilon-\xi_n^\wedge < 0\)
故 \(\alpha _n^\wedge =0\) - 此時 \(\mathbf{w}=\sum_{n=1}^{N}(\alpha _n^\wedge-\alpha _n^\vee)\mathbf{z}_n\)
\((\alpha _n^\wedge-\alpha _n^\vee)=0\) 也就是 \(\beta_n =0\)
達到 sparse \(\boldsymbol\beta\) 的要求,只有在 tube 邊界和以外的才是 SV
Model 總結
- \(s= \mathbf{w}^T\mathbf{z}_n+b\)
- 分類
- linear
- PLA/pocket
- \(err_{0/1}(s,y)=[ys\le0]\)
- solver : update
- 不常用,表現不好
- linear soft-margin SVM
- \(\widehat{err}_{SVM}(s,y)=max(1-ys,0)\)
- solver : QP
- librabry:LIBLINEAR
- kernel
- SVM
- \(\widehat{err}_{SVM}(s,y)=max(1-ys,0)\),dual SVM
- solver : QP
- librabry:LIBSVM
- 回歸
- linear
- linear SVR
- \(err_{tube}=max(0,|s-y|-\epsilon) \)
- solver : QP
- 不常用,表現不好
- linear ridge regression
- \(err_{SQR}=(s-y)^2\)
- solver : 分析求解
- librabry:LIBLINEAR
- kernel
- kernel ridge regression (KRR)
- \(err_{SQR}=(s-y)^2\)
- solver : 分析求解
- 不常用,效率不好
- SVR
- \(err_{tube}=max(0,|s-y|-\epsilon) \)
- solver : QP
- librabry:LIBSVM
- 機率預測
- linear
- regularized logistic reression
- \(err_{CE}=ln (1+e^{-y\mathbf{s}})\)
- solver : GD/SGD
- librabry:LIBLINEAR
- kernel
- kernel logistic regression (KLR)
- \(err_{CE}=ln (1+e^{-y\mathbf{s}})\)
- solver : GD/SGD
- 不常用,效率不好
- probabilistic SVM
- \(\widehat{err}_{SVM}(s,y)=max(1-ys,0)\)
\(err_{CE}=ln (1+e^{-y\mathbf{s}})\) - solver : QP -> GD/SGD
- librabry:LIBSVM
- kernel model 務必小心 overfitting
程式碼
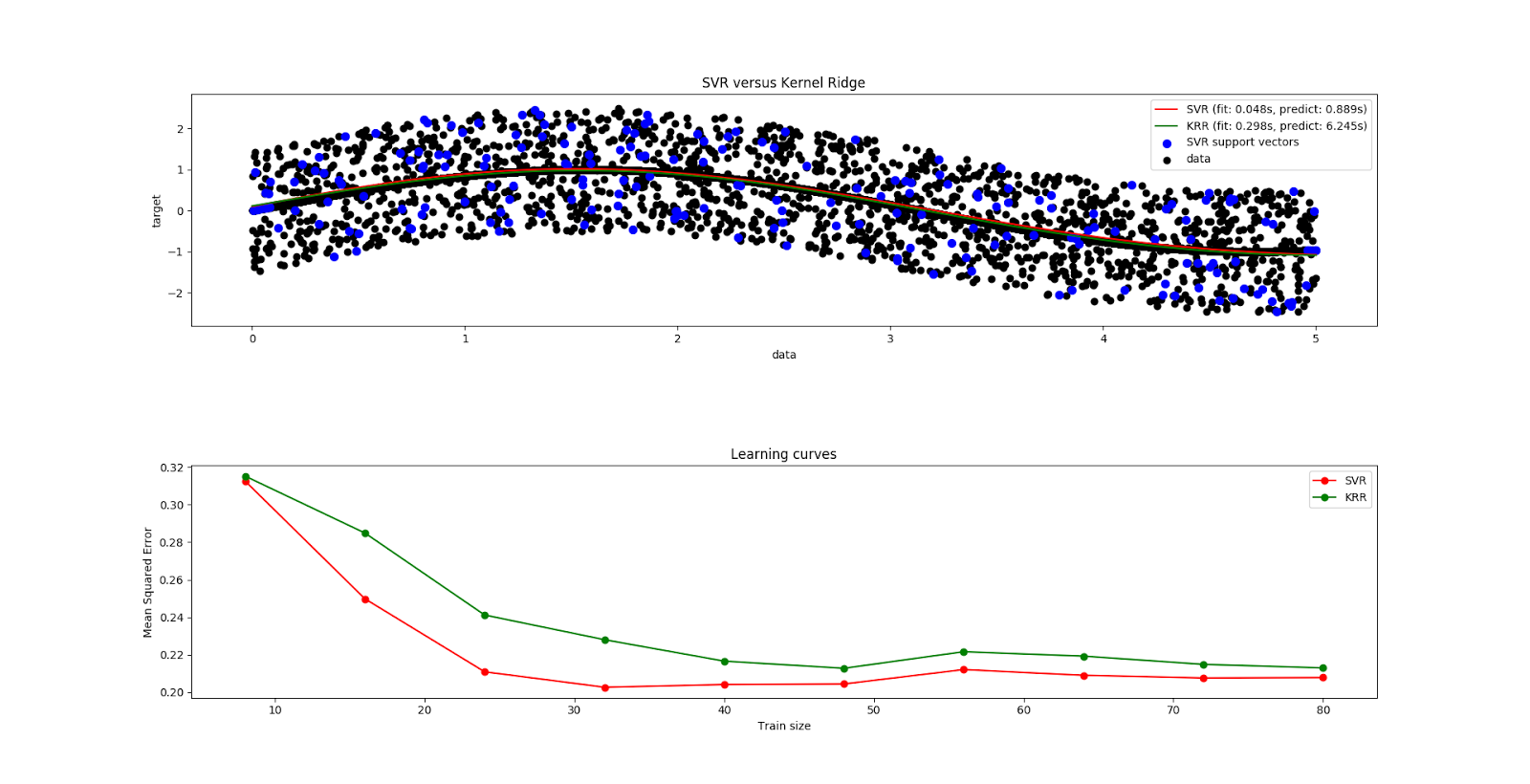
from __future__ import division
import time
import numpy as np
from sklearn.svm import SVR
from sklearn.kernel_ridge import KernelRidge
from sklearn.model_selection import learning_curve
import matplotlib.pyplot as plt
# 設定 seed
rng = np.random.RandomState(0)
# 訓練資料
X = 5 * rng.rand(10000, 1)
y = np.sin(X).ravel()
# 加入 noise
y[::5] += 3 * (0.5 - rng.rand(X.shape[0] // 5))
# 畫圖的資料,新增二維維度
X_plot = np.linspace(0, 5, 100000)[:, None]
# 訓練大小
train_size = 1000
# model
svr = SVR(kernel='rbf', gamma=0.1, epsilon=0.1)
krr = KernelRidge(kernel='rbf', gamma=0.1)
# 計算 SVR 訓練時間
t0 = time.time()
svr.fit(X[:train_size], y[:train_size])
svr_fit = time.time() - t0
print("SVR complexity and bandwidth selected and model fitted in %.3f s"
% svr_fit)
# 計算 KRR 訓練時間
t0 = time.time()
krr.fit(X[:train_size], y[:train_size])
krr_fit = time.time() - t0
print("KRR complexity and bandwidth selected and model fitted in %.3f s"
% krr_fit)
# 計算 SVR 預測時間
t0 = time.time()
y_svr = svr.predict(X_plot)
svr_predict = time.time() - t0
print("SVR prediction for %d inputs in %.3f s"
% (X_plot.shape[0], svr_predict))
# 計算 KRR 預測時間
t0 = time.time()
y_krr = krr.predict(X_plot)
krr_predict = time.time() - t0
print("KRR prediction for %d inputs in %.3f s"
% (X_plot.shape[0], krr_predict))
# SVR 的 support vector
sv_ind = svr.support_
plt.subplot(2,1,1)
# 畫出 SV
plt.scatter(X[sv_ind], y[sv_ind], c='b', s=50, label='SVR support vectors', zorder=2)
# 畫出 data
plt.scatter(X[:], y[:], c='k', label='data', zorder=1)
# 畫出 SVR 的曲線
plt.plot(X_plot, y_svr, c='r',
label='SVR (fit: %.3fs, predict: %.3fs)' % (svr_fit, svr_predict))
# 畫出 KRR 的曲線
plt.plot(X_plot, y_krr, c='g',
label='KRR (fit: %.3fs, predict: %.3fs)' % (krr_fit, krr_predict))
plt.xlabel('data')
plt.ylabel('target')
plt.title('SVR versus Kernel Ridge')
plt.legend()
# Visualize learning curves
plt.subplot(2,1,2)
# model
svr = SVR(kernel='rbf', C=1e1, gamma=0.1, epsilon=0.1)
krr = KernelRidge(kernel='rbf', alpha=0.1, gamma=0.1)
# cv = cross-validation,5 表示五份
train_sizes, train_scores_svr, test_scores_svr = \
learning_curve(svr, X[:100], y[:100], train_sizes=np.linspace(0.1, 1, 10),
scoring="neg_mean_squared_error", cv=5)
train_sizes_abs, train_scores_krr, test_scores_krr = \
learning_curve(krr, X[:100], y[:100], train_sizes=np.linspace(0.1, 1, 10),
scoring="neg_mean_squared_error", cv=5)
plt.plot(train_sizes, -test_scores_svr.mean(1), 'o-', color="r",
label="SVR")
plt.plot(train_sizes, -test_scores_krr.mean(1), 'o-', color="g",
label="KRR")
plt.xlabel("Train size")
plt.ylabel("Mean Squared Error")
plt.title('Learning curves')
plt.legend(loc="best")
# 調整之間的空白高度
plt.subplots_adjust(hspace=0.6)
plt.show()
參考
sklearn.kernel_ridge.KernelRidgesklearn.svm.SVR
sklearn.model_selection.learning_curve
留言
張貼留言